
تحلیل بقا که به آن Survival Analysis گفته میشود، ابزار و روشی است جهت بررسی این مطلب که چگونه احتمال وقوع یک رویداد معین، با گذر زمان کم و یا زیاد میشود.
به این ترتیب ما در آنالیز بقا، با سه کلمهی اساسی که تشکیل دهندهی این نوع از تحلیلهای آماری هستند، روبهرو هستیم. این سه کلمه عبارتند از
احتمال، رویداد و زمان.
احتمال و زمان که مفاهیم شناخته شدهای هستند. آنچه باقی میماند واژه رویداد و پاسخ به این سوال است که شما میخواهید احتمال وقوع کدام رویداد وابسته به زمان را محاسبه کنید.
در اینجا ما با طیف وسیعی از رویدادهای مورد علاقه در علوم مختلف روبهرو هستیم. هر چند که آنالیز بقا همانگونه که از نام آن برمیآید در تحلیلهای آمار پزشکی و حیاتی ریشه دارد، منتهی کاملاً قابلیت تطابق و استفاده در سایر علوم را نیز دارد.
من از روزهای ابتدایی زمستان سال گذشته تا انتهای دیماه، نُه (9) جلسه کلاس در موضوع آنالیز بقا داشتم. در این جلسات از مفاهیم مقدماتی تا کار با نرمافزار Prism بیان شده است.
گراف پد متن نوشتاری و ویدئویی این کلاسها را در سایت خود قرار داده است. علاقمند بودید آنها را ببینید و مطالعه کنید.
جلسه اول. مفاهیم و تعاریف اساسی در آنالیز بقا
جلسه دوم. دادههای سانسور شده Censored Data
جلسه سوم. نسبت خطر Hazard Ratio چیست؟
جلسه چهارم. تحلیلهای کاپلان مایر Kaplan-Meier
جلسه پنجم. میانه بقا Median Survival چیست؟
جلسه ششم. خطرات Hazards و نرخ خطر Hazard Rate
جلسه هفتم. رگرسیون خطرات متناسب کاکس Cox Proportional Hazards Regression
جلسه هشتم. باقیمانده ها Residuals در رگرسیون خطرات متناسب کاکس
جلسه نهم. تنظیمات رسم نمودار ها Graphs در رگرسیون Cox
به این ترتیب ما در آنالیز بقا، با سه کلمهی اساسی که تشکیل دهندهی این نوع از تحلیلهای آماری هستند، روبهرو هستیم. این سه کلمه عبارتند از
احتمال، رویداد و زمان.
احتمال و زمان که مفاهیم شناخته شدهای هستند. آنچه باقی میماند واژه رویداد و پاسخ به این سوال است که شما میخواهید احتمال وقوع کدام رویداد وابسته به زمان را محاسبه کنید.
در اینجا ما با طیف وسیعی از رویدادهای مورد علاقه در علوم مختلف روبهرو هستیم. هر چند که آنالیز بقا همانگونه که از نام آن برمیآید در تحلیلهای آمار پزشکی و حیاتی ریشه دارد، منتهی کاملاً قابلیت تطابق و استفاده در سایر علوم را نیز دارد.
من از روزهای ابتدایی زمستان سال گذشته تا انتهای دیماه، نُه (9) جلسه کلاس در موضوع آنالیز بقا داشتم. در این جلسات از مفاهیم مقدماتی تا کار با نرمافزار Prism بیان شده است.
گراف پد متن نوشتاری و ویدئویی این کلاسها را در سایت خود قرار داده است. علاقمند بودید آنها را ببینید و مطالعه کنید.
جلسه اول. مفاهیم و تعاریف اساسی در آنالیز بقا
جلسه دوم. دادههای سانسور شده Censored Data
جلسه سوم. نسبت خطر Hazard Ratio چیست؟
جلسه چهارم. تحلیلهای کاپلان مایر Kaplan-Meier
جلسه پنجم. میانه بقا Median Survival چیست؟
جلسه ششم. خطرات Hazards و نرخ خطر Hazard Rate
جلسه هفتم. رگرسیون خطرات متناسب کاکس Cox Proportional Hazards Regression
جلسه هشتم. باقیمانده ها Residuals در رگرسیون خطرات متناسب کاکس
جلسه نهم. تنظیمات رسم نمودار ها Graphs در رگرسیون Cox
من در کانال گراف پد، دربارهی Heavy-Tailed بودن توزیع بازده سهام به ویژه برای سال 1402 صحبت کردم. میتوانید این متن و همچنین این نوشته را ببینید.
چند روز پیش مقالهای با عنوان
An alternative stochastic model for linear portfolios
مشاهده کردم که توسط دو نویسنده به نامهای Ismet birbiçer و Ali I. Genc (این فرد در زمینه elliptical distributions و ساختن توزیعهای جدید آماری معروف است) از دانشگاه Cukurova University (ترکیه)، نوشته شده بود.
این مقاله به تازگی در ژورنال
Communications in Statistics - Simulation and Computation, Volume 52, Issue 4 (2023)
دانشگاه میشیگان آمریکا چاپ شده است.
در این مقاله به صراحت نوشته شده است که
Stock market returns often tend to follow a non-normal probability distribution due to extreme losses in the tails. These cause fatter tails than normal and consequently heavy-tailed probability distributions are mostly used for modeling returns.
خواندن این مقاله را که به مدلسازی ریاضی و آماری portfolio و بررسی هفت real stocks پرداخته است، به شما پیشنهاد میکنم.
چند روز پیش مقالهای با عنوان
An alternative stochastic model for linear portfolios
مشاهده کردم که توسط دو نویسنده به نامهای Ismet birbiçer و Ali I. Genc (این فرد در زمینه elliptical distributions و ساختن توزیعهای جدید آماری معروف است) از دانشگاه Cukurova University (ترکیه)، نوشته شده بود.
این مقاله به تازگی در ژورنال
Communications in Statistics - Simulation and Computation, Volume 52, Issue 4 (2023)
دانشگاه میشیگان آمریکا چاپ شده است.
در این مقاله به صراحت نوشته شده است که
Stock market returns often tend to follow a non-normal probability distribution due to extreme losses in the tails. These cause fatter tails than normal and consequently heavy-tailed probability distributions are mostly used for modeling returns.
خواندن این مقاله را که به مدلسازی ریاضی و آماری portfolio و بررسی هفت real stocks پرداخته است، به شما پیشنهاد میکنم.
از گذشته برای خودم سوال بود، هنگامی که شاخص به عدد سقف قبلی یعنی 2.1 میلیون در سال 99 برسد، وضعیت سبدها چگونه خواهد بود؟
برای پاسخ به این سوال من یک شبیهسازی با جامعه آماری حدود 80 هزار نفری انجام دادم. در این شبیهسازی میلیونها حالت و ترکیب احتمالی متفاوت از خرید و فروش همه نمادها توسط این 80 هزار نفر شبیهسازی شده، بررسی شده است.
در این مدل، من دو گروه از افراد (سبدها) را کنار گذاشتم و از مطالعه خارج کردم.
1- آنهایی که به هر دلیلی در فاصله بین سقف قبلی 2.1 تا زمان رسیدن به همان عدد 2.1 میلیون، از بازار خارج شدهاند و سبدهای خود را صفر کردهاند.
2- سبدهایی که صرفاً دارای عرضه اولیههای ارایه شده در بازه زمانی مرداد 99 تا فروردین 402 بودهاند.
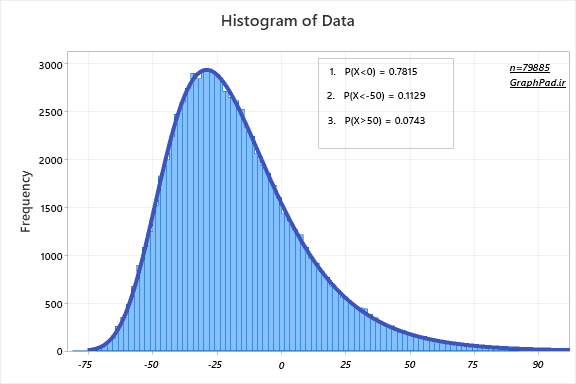
در گراف زیر توزیع فراوانی بازدهی سبدهای 80 هزار نفر شبیهسازی شده، هنگامی که شاخص دوباره به سقف قبلی خود بازگشته است، ارایه شده است. چند نکته دربارهی آن نوشتهام.
الف) 78.15 درصد افراد دارای سبدهای با ارزش کمتر از دفعه قبل هستند. به عبارت ساده، شاخص به جای خود بازگشته منتهی برای حدود 78 درصد افراد، ارزش سبدها به جای خود بازنگشته.
ب) 11.29 درصد افراد، سبدهایی با افت بیشتر از 50 درصد را تجربه میکنند.
پ) برای 7.43 درصد افراد، ارزش سبدها بیشتر از 50 درصد، نسبت به زمانی که شاخص 2.1 میلیون بوده، رشد داشته است.
https://graphpad.ir/wp-content/uploads/2023/04/Histogram-of-Data-GraphPad.ir_.png
برای پاسخ به این سوال من یک شبیهسازی با جامعه آماری حدود 80 هزار نفری انجام دادم. در این شبیهسازی میلیونها حالت و ترکیب احتمالی متفاوت از خرید و فروش همه نمادها توسط این 80 هزار نفر شبیهسازی شده، بررسی شده است.
در این مدل، من دو گروه از افراد (سبدها) را کنار گذاشتم و از مطالعه خارج کردم.
1- آنهایی که به هر دلیلی در فاصله بین سقف قبلی 2.1 تا زمان رسیدن به همان عدد 2.1 میلیون، از بازار خارج شدهاند و سبدهای خود را صفر کردهاند.
2- سبدهایی که صرفاً دارای عرضه اولیههای ارایه شده در بازه زمانی مرداد 99 تا فروردین 402 بودهاند.
در گراف زیر توزیع فراوانی بازدهی سبدهای 80 هزار نفر شبیهسازی شده، هنگامی که شاخص دوباره به سقف قبلی خود بازگشته است، ارایه شده است. چند نکته دربارهی آن نوشتهام.
الف) 78.15 درصد افراد دارای سبدهای با ارزش کمتر از دفعه قبل هستند. به عبارت ساده، شاخص به جای خود بازگشته منتهی برای حدود 78 درصد افراد، ارزش سبدها به جای خود بازنگشته.
ب) 11.29 درصد افراد، سبدهایی با افت بیشتر از 50 درصد را تجربه میکنند.
پ) برای 7.43 درصد افراد، ارزش سبدها بیشتر از 50 درصد، نسبت به زمانی که شاخص 2.1 میلیون بوده، رشد داشته است.
https://graphpad.ir/wp-content/uploads/2023/04/Histogram-of-Data-GraphPad.ir_.png
{kind=link}
الف) فرض کنید n نفر فرضی (مثلاً ۱۰۰۰ نفر) روز دوشنبه ۲۰ مرداد سال ۱۳۹۹ و بر روی شاخص ۲.۱ میلیون، برای اولین بار وارد بازار سرمایه شده و به تصادف سهام میخرند. چه نمادهایی و به چه مقدار مهم نیست.
سپس پی کار خودشان میروند و کاملاً فراموش میکنند که وارد بازار شده و سهام خریدهاند. ما به این افراد، گروه غیرفعال میگوییم.
فرض کنید این افراد در روز سهشنبه ۱۵ فروردین ۱۴۰۲ که شاخص دوباره به عدد ۲.۱ میلیون رسیده، سبد خود را نگاه میکنند. چه اتفاقی برای سبد آنها افتاده؟
واضح است که هر کدام عملکردی دارند. یکی ارزش سبدش دو برابر شده، دیگری نصف دفعه قبل هم نیست و یکی دیگر مثلاً ۲۰ درصد در ضرر است.
سوال این است که عمده (میانه) افراد غیرفعال چگونه هستند؟
پاسخ این است که یک براورد فاصلهای Confidence Interval از اختلاف بین ارزش سبد این افراد در روز ۲۰ مرداد ۹۹ با ۱۵ فروردین ۴۰۲ نشان میدهد، میزان ضرر آنها در یک بازه (۱۷-۱۵) درصد قرار دارد.
این بازه را میتوان انحراف خالص شاخص از خودش نامید و البته موضوع بحث من در این نوشته نیست.
بنابراین به عبارت ساده، ارزش سبد میانه افرادی که در روز ۲۰ مرداد ۹۹ وارد بازار شدهاند و سپس فعالیتی در بازار نداشته و خربد و فروشی انجام ندادهاند، نسبت به روزی که شاخص دوباره در روز ۱۵ فروردین ۴۰۲ به عدد قبلی بازگشته، ۱۵ تا ۱۷ درصد کمتر شده است.
ب) ۱۰۰۰ نفر فرضی دیگر را در نظر بگیرید که آنها هم دقیقاً مانند گروه الف) در روز دوشنبه ۲۰ مرداد سال ۱۳۹۹ و بر روی شاخص ۲.۱ میلیون، وارد بازار شدهاند. آنها هم به تصادف نمادهایی را خریداری کردهاند.
منتهی برخلاف گروه قبلی در بازار حضور فعال داشتهاند. به این معنا که بر مبنای منطق و دلیل خودشان در بازار خرید و فروش میکردند. از نماد X به نماد Y و از Y به Z و همینطور نمادهای دیگر.
سوال این است، مقدار ارزش ریالی سبد این افراد در روز سهشنبه ۱۵ فروردین ۱۴۰۲ که شاخص دوباره به عدد ۲.۱ میلیون رسیده، چگونه است؟
پاسخ به این سوال در متن قبلی و گراف آن دیده میشود. پیک و نقطه اوج گراف را نگاه کنید. در یک مدل شبیهسازی، نشان داده شد که میانه افراد در ضرر حدود (۲۶-۲۴) درصد هستند.
من در گراف زیر، توزیع احتمالی انحراف سبد افراد هم در گروه الف) غیرفعال و هم در گروه ب) فعال را رسم کردهام. این گراف نشان میدهد، میانه افراد غیرفعال، در ضرر حدود ۱۶ درصد و میانه افراد فعال، در ضرر حدود ۲۵ درصد هستند.
در این زمینه بیان چند نکته ضروری است.
۱- اینگونه نیست که همهی ۱۰۰۰ نفر فرضی غیرفعال دارای نتیجه بهتری از همه ۱۰۰۰ نفر افراد فعال هستند. این نتیجه ساده را میتوان از همپوشانی دو گراف زیر نیز به دست آورد.
در این تحلیل، ما از میانهها یعنی عمده افراد حرف میزنیم و نتیجه ساده هم این است که بیشتر افراد غیرفعال دارای نتیجه بهتری نسبت به افراد فعال هستند.
۲- طبیعی است که فکر کنیم همه افراد فعال، در هر موقعیت خرید یا فروش در فاصله زمانی (مرداد ۹۹ تا فروردین ۴۰۲) که قرار گرفتهاند، بر این نظر بودهاند که کار درستی انجام میدهند و ترید آنها منجر به عملکرد بهتری برایشان خواهد شد.
با این حال آنچه در پایان داستان به دست آمده این است که عمده افراد (میانه) چنانچه کاری نمیکردند، نتیجه بهتری به دست میآوردند.
https://graphpad.ir/wp-content/uploads/2023/05/Deviation-of-Data-GraphPad.ir_.png
سپس پی کار خودشان میروند و کاملاً فراموش میکنند که وارد بازار شده و سهام خریدهاند. ما به این افراد، گروه غیرفعال میگوییم.
فرض کنید این افراد در روز سهشنبه ۱۵ فروردین ۱۴۰۲ که شاخص دوباره به عدد ۲.۱ میلیون رسیده، سبد خود را نگاه میکنند. چه اتفاقی برای سبد آنها افتاده؟
واضح است که هر کدام عملکردی دارند. یکی ارزش سبدش دو برابر شده، دیگری نصف دفعه قبل هم نیست و یکی دیگر مثلاً ۲۰ درصد در ضرر است.
سوال این است که عمده (میانه) افراد غیرفعال چگونه هستند؟
پاسخ این است که یک براورد فاصلهای Confidence Interval از اختلاف بین ارزش سبد این افراد در روز ۲۰ مرداد ۹۹ با ۱۵ فروردین ۴۰۲ نشان میدهد، میزان ضرر آنها در یک بازه (۱۷-۱۵) درصد قرار دارد.
این بازه را میتوان انحراف خالص شاخص از خودش نامید و البته موضوع بحث من در این نوشته نیست.
بنابراین به عبارت ساده، ارزش سبد میانه افرادی که در روز ۲۰ مرداد ۹۹ وارد بازار شدهاند و سپس فعالیتی در بازار نداشته و خربد و فروشی انجام ندادهاند، نسبت به روزی که شاخص دوباره در روز ۱۵ فروردین ۴۰۲ به عدد قبلی بازگشته، ۱۵ تا ۱۷ درصد کمتر شده است.
ب) ۱۰۰۰ نفر فرضی دیگر را در نظر بگیرید که آنها هم دقیقاً مانند گروه الف) در روز دوشنبه ۲۰ مرداد سال ۱۳۹۹ و بر روی شاخص ۲.۱ میلیون، وارد بازار شدهاند. آنها هم به تصادف نمادهایی را خریداری کردهاند.
منتهی برخلاف گروه قبلی در بازار حضور فعال داشتهاند. به این معنا که بر مبنای منطق و دلیل خودشان در بازار خرید و فروش میکردند. از نماد X به نماد Y و از Y به Z و همینطور نمادهای دیگر.
سوال این است، مقدار ارزش ریالی سبد این افراد در روز سهشنبه ۱۵ فروردین ۱۴۰۲ که شاخص دوباره به عدد ۲.۱ میلیون رسیده، چگونه است؟
پاسخ به این سوال در متن قبلی و گراف آن دیده میشود. پیک و نقطه اوج گراف را نگاه کنید. در یک مدل شبیهسازی، نشان داده شد که میانه افراد در ضرر حدود (۲۶-۲۴) درصد هستند.
من در گراف زیر، توزیع احتمالی انحراف سبد افراد هم در گروه الف) غیرفعال و هم در گروه ب) فعال را رسم کردهام. این گراف نشان میدهد، میانه افراد غیرفعال، در ضرر حدود ۱۶ درصد و میانه افراد فعال، در ضرر حدود ۲۵ درصد هستند.
در این زمینه بیان چند نکته ضروری است.
۱- اینگونه نیست که همهی ۱۰۰۰ نفر فرضی غیرفعال دارای نتیجه بهتری از همه ۱۰۰۰ نفر افراد فعال هستند. این نتیجه ساده را میتوان از همپوشانی دو گراف زیر نیز به دست آورد.
در این تحلیل، ما از میانهها یعنی عمده افراد حرف میزنیم و نتیجه ساده هم این است که بیشتر افراد غیرفعال دارای نتیجه بهتری نسبت به افراد فعال هستند.
۲- طبیعی است که فکر کنیم همه افراد فعال، در هر موقعیت خرید یا فروش در فاصله زمانی (مرداد ۹۹ تا فروردین ۴۰۲) که قرار گرفتهاند، بر این نظر بودهاند که کار درستی انجام میدهند و ترید آنها منجر به عملکرد بهتری برایشان خواهد شد.
با این حال آنچه در پایان داستان به دست آمده این است که عمده افراد (میانه) چنانچه کاری نمیکردند، نتیجه بهتری به دست میآوردند.
https://graphpad.ir/wp-content/uploads/2023/05/Deviation-of-Data-GraphPad.ir_.png
Telegram
GraphPad
از گذشته برای خودم سوال بود، هنگامی که شاخص به عدد سقف قبلی یعنی 2.1 میلیون در سال 99 برسد، وضعیت سبدها چگونه خواهد بود؟
برای پاسخ به این سوال من یک شبیهسازی با جامعه آماری حدود 80 هزار نفری انجام دادم. در این شبیهسازی میلیونها حالت و ترکیب احتمالی…
برای پاسخ به این سوال من یک شبیهسازی با جامعه آماری حدود 80 هزار نفری انجام دادم. در این شبیهسازی میلیونها حالت و ترکیب احتمالی…
من در این متن نوشتم که میانه انحراف ارزش سبد افراد فعال در بازار سرمایه از 20 مرداد 99 تا 15 فروردین 402 (نقطهای که شاخص دوباره به عدد خود بازگشته است) در بازه (26-24) درصد منفی قرار دارد. همین عدد یعنی میانه انحراف ارزش سبد برای افراد غیرفعال در بازه (17-15) درصد منفی قرار گرفته است.
بنابراین به بیان ساده، شاخص در روز 15 فروردین 402 به مقدار 2.1 میلیون سقف قبلی خود بازگشته بود، با اینحال ارزش سبد میانه افراد (چه فعال و چه غیرفعال) همچنان منفی بود.
حال یک سوال مهم از خودمان بپرسیم و سعی کنیم به آن پاسخ دهیم.
عدد شاخص تا چه اندازه باید جلوتر میرفت تا ارزش سبد میانه افراد از مقدار منفی خارج و اصطلاحاً سربهسر شود؟ عدد خالص شاخص بدون انحراف، جهت سربهسر شدن ارزش سبدها، چند بوده است؟
نکتهای که وجود دارد این است که شاخص کل از روز 15 فروردین 402 تا شنبه 16 اردیبهشت، به عدد 2.53 میلیون واحد رسیده بود یعنی حدود 19.6% افزایش.
جالب است که بدانیم شاخص میانه در این مدت عملکرد بهتری از شاخص کل داشته است و مقدار افزایش آن حدود 22.7 درصد بوده است.
خب، اینها یعنی چه؟
یعنی اینکه شاخص کل و بازار سرمایه صرفاً تا آنجایی جلو رفته که در لبههای مرز سربهسر شدن ارزش سبد میانه افراد فعال (و کمی جلوتر از افراد غیرفعال) نسبت به مرداد 99 قرار گیرد. شاخص جلوتر از این لبهها حرکت نکرده و نرفته است.
به عبارت دیگر، عدد دقیق شاخص کل، برای رسیدن به ارزش سبد سربهسر با مرداد 99، برای میانه افراد، مقدار 2.57 میلیون واحد بوده است، که خب شاخص تا نزدیکهای این عدد رسیده و سپس بار دیگر ارزش سبدها را منفی کرده است.
من از بیان این موضوع میخواهم به دو نتیجه برسم.
الف) عدد 2.53 تا 2.57 میلیون واحد، مقداری برای شاخص کل بوده است که میانه افراد به ارزش ریالی سربهسر سبد خود نسبت به مرداد 99 رسیدهاند. البته نقش این افراد در ریزش 200 هزار واحدی این دو روز چندان برجسته نیست.
ب) من در این متن که آن را در مرداد سال 401 نوشتم، بیان کردم که انتهای هنر بازارساز، کار کردن و تحلیل با اکسل است.
با این حال اینبار و در اردیبهشت سال 402 باید بنویسم که بازار ساز از فضای سادهلوحانه اکسل فاصله گرفته و عدد دقیق سربهسر شدن میانه افراد را به درستی تشخیص داده است.
تصمیم عامدانه ریزش با همان محدوده سربهسر شدن میانه افراد، تلاقی پیدا کرده است که البته ابزار مستندی در اختیار نداریم که بدانیم این تلاقی نتیجه یک برنامهریزی بوده و یا اتفاقی تصادفی رخ داده است.
اگر این سوال را چند ماه پیش از من میپرسیدید با اطمینان زیادی میگفتم که این تلاقی حاصل یک اتفاق تصادفی بوده است. با این حال رفتار حرفهای تیم بازارساز در این چند ماه، میتواند ذهنیت را به سمت یک برنامهریزی سوق دهد.
اما آینده.
همچنان ایده من Heavy-Tailed بودن توزیع بازده سهام در سال 402 است. علاقمند بودید این نوشته و این نوشته را بخوانید.
غیرنرمال بودن دادهها، رفتار آونگی نمادها از مثبت بزرگ به منفی بزرگ و بالعکس، سود و ضرر زیاد برای تعداد افراد زیاد، عدم صفر بودن و یا نزدیک به صفر بودن بتای بازدهی سهام و بلکه مثبت بزرگ و منفی بزرگ بتای بازدهی، از ویژگیهای این نوع خانواده توزیعهای آماری میباشد.
بنابراین به بیان ساده، شاخص در روز 15 فروردین 402 به مقدار 2.1 میلیون سقف قبلی خود بازگشته بود، با اینحال ارزش سبد میانه افراد (چه فعال و چه غیرفعال) همچنان منفی بود.
حال یک سوال مهم از خودمان بپرسیم و سعی کنیم به آن پاسخ دهیم.
عدد شاخص تا چه اندازه باید جلوتر میرفت تا ارزش سبد میانه افراد از مقدار منفی خارج و اصطلاحاً سربهسر شود؟ عدد خالص شاخص بدون انحراف، جهت سربهسر شدن ارزش سبدها، چند بوده است؟
نکتهای که وجود دارد این است که شاخص کل از روز 15 فروردین 402 تا شنبه 16 اردیبهشت، به عدد 2.53 میلیون واحد رسیده بود یعنی حدود 19.6% افزایش.
جالب است که بدانیم شاخص میانه در این مدت عملکرد بهتری از شاخص کل داشته است و مقدار افزایش آن حدود 22.7 درصد بوده است.
خب، اینها یعنی چه؟
یعنی اینکه شاخص کل و بازار سرمایه صرفاً تا آنجایی جلو رفته که در لبههای مرز سربهسر شدن ارزش سبد میانه افراد فعال (و کمی جلوتر از افراد غیرفعال) نسبت به مرداد 99 قرار گیرد. شاخص جلوتر از این لبهها حرکت نکرده و نرفته است.
به عبارت دیگر، عدد دقیق شاخص کل، برای رسیدن به ارزش سبد سربهسر با مرداد 99، برای میانه افراد، مقدار 2.57 میلیون واحد بوده است، که خب شاخص تا نزدیکهای این عدد رسیده و سپس بار دیگر ارزش سبدها را منفی کرده است.
من از بیان این موضوع میخواهم به دو نتیجه برسم.
الف) عدد 2.53 تا 2.57 میلیون واحد، مقداری برای شاخص کل بوده است که میانه افراد به ارزش ریالی سربهسر سبد خود نسبت به مرداد 99 رسیدهاند. البته نقش این افراد در ریزش 200 هزار واحدی این دو روز چندان برجسته نیست.
ب) من در این متن که آن را در مرداد سال 401 نوشتم، بیان کردم که انتهای هنر بازارساز، کار کردن و تحلیل با اکسل است.
با این حال اینبار و در اردیبهشت سال 402 باید بنویسم که بازار ساز از فضای سادهلوحانه اکسل فاصله گرفته و عدد دقیق سربهسر شدن میانه افراد را به درستی تشخیص داده است.
تصمیم عامدانه ریزش با همان محدوده سربهسر شدن میانه افراد، تلاقی پیدا کرده است که البته ابزار مستندی در اختیار نداریم که بدانیم این تلاقی نتیجه یک برنامهریزی بوده و یا اتفاقی تصادفی رخ داده است.
اگر این سوال را چند ماه پیش از من میپرسیدید با اطمینان زیادی میگفتم که این تلاقی حاصل یک اتفاق تصادفی بوده است. با این حال رفتار حرفهای تیم بازارساز در این چند ماه، میتواند ذهنیت را به سمت یک برنامهریزی سوق دهد.
اما آینده.
همچنان ایده من Heavy-Tailed بودن توزیع بازده سهام در سال 402 است. علاقمند بودید این نوشته و این نوشته را بخوانید.
غیرنرمال بودن دادهها، رفتار آونگی نمادها از مثبت بزرگ به منفی بزرگ و بالعکس، سود و ضرر زیاد برای تعداد افراد زیاد، عدم صفر بودن و یا نزدیک به صفر بودن بتای بازدهی سهام و بلکه مثبت بزرگ و منفی بزرگ بتای بازدهی، از ویژگیهای این نوع خانواده توزیعهای آماری میباشد.
در 21 March سال 2023 (اولین روز فروردین امسال) فردی به نام Chetna Chauhan از دانشگاه Los Andes کشور کلمبیا، سوالی در ریسرچگیت مطرح کرد که زمینهساز بحثهای زیادی در میان پژوهشگران آماری دنیا قرار گرفت.
سوال او بر این مبنا بود که وقتی در آمار تئوری با نام قضیه حد مرکزی Central Limit Theorem وجود دارد که میگوید هنگامی که تعداد دادهها به اندازه کافی زیاد باشد، دادهها به سمت توزیع نرمال شدن، حرکت میکنند و همچنین روشهایی جهت نرمال کردن دادهها (داستان یکی از آنها را من در این نوشته، بیان کردم)، بنابراین دیگر چه لزومی دارد که از آزمونهای ناپارامتری که جهت تحلیل بر روی دادههای غیرنرمال، ساخته و ابداع شدهاند، استفاده کنیم؟
در این لینک میتوانید سوال او و پاسخها را مشاهده کنید.
در این زمینه چند نکته وجود دارد.
1- چنانچه به مباحث آماری علاقمند هستید، لینک بالا را ببینید. این سوال توسط بهترین اساتید آمار حال حاضر دنیا مانند Jochen Wilhelm آلمانی و Bruce Weaver کانادایی و همچنین Daniel Wright آمریکایی پاسخ داده و یا ریکامند شده است.
2- قضیه حد مرکزی (CLT) در تحلیل بازده سهام، طراحی سبد بهینه و مدیریت ریسک، میتواند مورد استفاده قرار گیرد. در این زمینه میتوانید این لینک و مقاله را ببینید. همهی شبیهسازیهایی که من در کانال گراف پد از آنها نام بردهام، بر مبنای این قضیه انجام میشود.
3- خوب است این نکته را بگویم که آنچه در معمولاً به عنوان نرمال سازی دادهها از آن یاد میشود، صرفاً چیزی به نام استانداردسازی دادهها است. نرمال کردن دادهها فرایندی تا حدی پیچیده است و به معنای این است که تابع ریاضی و احتمالی دادهها از فرمول توزیع نرمال، پیروی کند و حداقل یکی از چهار آزمون اصلی نرمالیتی مانند کلوموگروف-اسمیرنف بیانگر نرمال بودن دادهها باشد.
4- قدیمیترین متون مربوط به تحلیلهای ناپارامتری مربوط به قرن 13 میلادی است. نوشتههایی مربوط به سال 1599 و یکی دیگر که به تحلیل نسبت جنسیت انسان در بدو تولد میپرداخت در سال 1710 نوشته شده است. این مطلب را از این جهت میگویم که بدانیم آزمونهای ناپارامتری دارای قدمت و تاریخچه هستند و طرفداران خاص خود را در دنیای حتی امروزی آمار دارند. بنابراین وجود روشها و تکنیکهایی که سبب شود آمار ناپارامتری حذف و یا بدون استفاده شود، برای آنها مطلوب نخواهد بود.
سوال Chetna Chauhan کلمبیایی، جرقهی مباحثی که البته چند سالی است مطرح شده را دوباره روشن کرد که اصولاً ما به آمار ناپارامتری و تحلیلهای مرتبط با آن نیازی داریم و یا خیر، آیا آنها باید برای همیشه حذف شوند؟
جهت پاسخ به این سوال که برای خود من هم ایجاد شده بود همانگونه که من در کنار سایر اساتید آمار تاپیک بالا در ریسرچ گیت، بیان کردم (در این لینک ببینید)، سبب شد که من روزهای فروردین سال 402 را به بررسی و مطالعه آزمونها و تحلیلهای ناپارامتری، بپردازم.
من 9 مقاله در این زمینه نوشته و در سایت گراف پد و ریسرچ گیت، منتشر کردم که در هر کدام از آنها به توضیح و کاربرد آنالیزهای ناپارامتری پرداختم. اسامی این مقالات را در ادامه نوشتهام.
مقاله اول. تحلیل ناپارامتری من ویتنی Mann-Whitney
مقاله دوم. آزمون کروسکال والیس Kruskal-Wallis H Test
مقاله سوم. آزمون ناپارامتری Jonckheere-Terpstra
مقاله چهارم. تحلیل رتبه علامت دار ویلکاکسون Wilcoxon Signed-Rank
مقاله پنجم. آزمون ناپارامتری کوکران Cochran's Q Test
مقاله ششم. تحلیل ناپارامتری همگنی حاشیه ای Marginal Homogeneity Test
مقاله هفتم. آزمون ناپارامتری علامت Sign Test
مقاله هشتم. تحلیل ناپارامتری فریدمن Friedman Test
مقاله نهم. ضریب تطابق کندال Kendall's Coefficient Of Concordance (W)
چنانچه به موضوعات آماری علاقمند بودید آنها را ببینید و بخوانید. نوشتن این مقالات و آشنا شدن بیشتر با دنیای آمار ناپارامتری سبب شد دیدگاه اولیه من که بر مبنای حذف و عدم کاربرد تحلیلهای ناپارامتری در تحلیل دادههای امروزی بود، اصلاح شده و دریابم که آنالیزهای ناپارامتری همچنان میتوانند مفید، موثر و دقیق باشند.
سوال او بر این مبنا بود که وقتی در آمار تئوری با نام قضیه حد مرکزی Central Limit Theorem وجود دارد که میگوید هنگامی که تعداد دادهها به اندازه کافی زیاد باشد، دادهها به سمت توزیع نرمال شدن، حرکت میکنند و همچنین روشهایی جهت نرمال کردن دادهها (داستان یکی از آنها را من در این نوشته، بیان کردم)، بنابراین دیگر چه لزومی دارد که از آزمونهای ناپارامتری که جهت تحلیل بر روی دادههای غیرنرمال، ساخته و ابداع شدهاند، استفاده کنیم؟
در این لینک میتوانید سوال او و پاسخها را مشاهده کنید.
در این زمینه چند نکته وجود دارد.
1- چنانچه به مباحث آماری علاقمند هستید، لینک بالا را ببینید. این سوال توسط بهترین اساتید آمار حال حاضر دنیا مانند Jochen Wilhelm آلمانی و Bruce Weaver کانادایی و همچنین Daniel Wright آمریکایی پاسخ داده و یا ریکامند شده است.
2- قضیه حد مرکزی (CLT) در تحلیل بازده سهام، طراحی سبد بهینه و مدیریت ریسک، میتواند مورد استفاده قرار گیرد. در این زمینه میتوانید این لینک و مقاله را ببینید. همهی شبیهسازیهایی که من در کانال گراف پد از آنها نام بردهام، بر مبنای این قضیه انجام میشود.
3- خوب است این نکته را بگویم که آنچه در معمولاً به عنوان نرمال سازی دادهها از آن یاد میشود، صرفاً چیزی به نام استانداردسازی دادهها است. نرمال کردن دادهها فرایندی تا حدی پیچیده است و به معنای این است که تابع ریاضی و احتمالی دادهها از فرمول توزیع نرمال، پیروی کند و حداقل یکی از چهار آزمون اصلی نرمالیتی مانند کلوموگروف-اسمیرنف بیانگر نرمال بودن دادهها باشد.
4- قدیمیترین متون مربوط به تحلیلهای ناپارامتری مربوط به قرن 13 میلادی است. نوشتههایی مربوط به سال 1599 و یکی دیگر که به تحلیل نسبت جنسیت انسان در بدو تولد میپرداخت در سال 1710 نوشته شده است. این مطلب را از این جهت میگویم که بدانیم آزمونهای ناپارامتری دارای قدمت و تاریخچه هستند و طرفداران خاص خود را در دنیای حتی امروزی آمار دارند. بنابراین وجود روشها و تکنیکهایی که سبب شود آمار ناپارامتری حذف و یا بدون استفاده شود، برای آنها مطلوب نخواهد بود.
سوال Chetna Chauhan کلمبیایی، جرقهی مباحثی که البته چند سالی است مطرح شده را دوباره روشن کرد که اصولاً ما به آمار ناپارامتری و تحلیلهای مرتبط با آن نیازی داریم و یا خیر، آیا آنها باید برای همیشه حذف شوند؟
جهت پاسخ به این سوال که برای خود من هم ایجاد شده بود همانگونه که من در کنار سایر اساتید آمار تاپیک بالا در ریسرچ گیت، بیان کردم (در این لینک ببینید)، سبب شد که من روزهای فروردین سال 402 را به بررسی و مطالعه آزمونها و تحلیلهای ناپارامتری، بپردازم.
من 9 مقاله در این زمینه نوشته و در سایت گراف پد و ریسرچ گیت، منتشر کردم که در هر کدام از آنها به توضیح و کاربرد آنالیزهای ناپارامتری پرداختم. اسامی این مقالات را در ادامه نوشتهام.
مقاله اول. تحلیل ناپارامتری من ویتنی Mann-Whitney
مقاله دوم. آزمون کروسکال والیس Kruskal-Wallis H Test
مقاله سوم. آزمون ناپارامتری Jonckheere-Terpstra
مقاله چهارم. تحلیل رتبه علامت دار ویلکاکسون Wilcoxon Signed-Rank
مقاله پنجم. آزمون ناپارامتری کوکران Cochran's Q Test
مقاله ششم. تحلیل ناپارامتری همگنی حاشیه ای Marginal Homogeneity Test
مقاله هفتم. آزمون ناپارامتری علامت Sign Test
مقاله هشتم. تحلیل ناپارامتری فریدمن Friedman Test
مقاله نهم. ضریب تطابق کندال Kendall's Coefficient Of Concordance (W)
چنانچه به موضوعات آماری علاقمند بودید آنها را ببینید و بخوانید. نوشتن این مقالات و آشنا شدن بیشتر با دنیای آمار ناپارامتری سبب شد دیدگاه اولیه من که بر مبنای حذف و عدم کاربرد تحلیلهای ناپارامتری در تحلیل دادههای امروزی بود، اصلاح شده و دریابم که آنالیزهای ناپارامتری همچنان میتوانند مفید، موثر و دقیق باشند.
{kind=link}
#Trend
آیا ابزار و روش تحلیلی وجود دارد که برای ما یک عدد تولید کند و ما با استفاده از آن عدد بگوییم، روند و گامهای بعدی دادهها صعودی – نزولی و یا فاقد روند (یکنواخت، ثابت) خواهد بود؟
پاسخ به این سوال مثبت است و میتوان از تحلیلی با نام آزمون روند خطی
Test for Linear Trend
نام برد.
این آزمون هنگامی که با نرمافزار Prism انجام میشود، علاوه بر بررسی وجود روند خطی، وجود روند غیرخطی را نیز تست میکند.
خب، حال بیایید به خروجیهای مهم Test for Linear Trend بپردازیم.
P-Trend
اولین یافته و شاید مهمترین آن، یک مقدار احتمال P-Value است. دوستانی که با مباحث آماری آشنا هستند میدانند در هر تست آماری P-Value ها به عنوان ابزار قضاوت آماری قرار میگیرند و به ما میگویند یافته معنادار است و یا معنادار نیست.
به عنوان مثال در یک تحلیل همبستگی، عدد به دست آمده از P-Value به ما میگوید ارتباط وجود دارد و یا وجود ندارد و یا در یک تحلیل مقایسهای به ما میگویند مشابهت و همانندی وجود دارد و یا وجود ندارد.
هنگامی که از
Test for Linear Trend
استفاده میکنیم به P-Value به دست آمده از این آزمون، اصطلاحاً P-Trend میگوییم.
عدد P-Trend همان عددی است که من در ابتدای متن از آن نام بردم. بیایید آن را بیشتر بشناسیم.
خوب است بدانیم P-Trend که همان P-Value سابق است، از جنس احتمال است و بنابراین به عنوان یک اندازه در بازه بین صفر و یک تعریف میشود. (دقت کنید هیچوقت صفر و یا یک به دست نمیآید) P نوشته شده در ابتدای نام آن به معنای Probability است.
این اتفاق بسیار مثبتی است. از دیدگاه آماری هر پارامتری که از جنس Probability باشد، قابلیت این را دارد که در چارچوب علمی قرار گیرد و وارد دنیای تئوری احتمال که خود بسیار گسترده است، شود. (در واقع ریشه تفاوت میان ریاضی و آمار همین است. ریاضیات به دنیای قطعیت و حتمیات میپردازد و آمار به دنیای احتمالات.)
گفتیم که P-Trend عددی احتمالی و در بازه صفر تا یک است. این عدد هرچقدر به یک نزدیکتر باشد به معنای عدم وجود روند در دادهها (پیشبینی ثابت و یکنواخت شدن) و هر چقدر به صفر نزدیکتر باشد به معنای ایجاد روند در دادهها (پیشبینی صعودی یا نزولی شدن) خواهد بود.
به عنوان مثال اگر P-Trend = 0.71 به دست بیاید، پیشبینی میکنیم دادهها با احتمال 71% فاقد Trend خواهند بود و با احتمال 29% روند به خود میگیرند. به همین ترتیب برای هر عدد دیگر به دست آمده از P-Trend میتوان چنین نتیجهای به دست آورد.
Slope
اصولاً ما وقتی نام شیب Slope را میشنویم به یاد مدلهای رگرسیونی و یا سری زمانی میافتیم. آزمون و روش تحلیل Test for Linear Trend که من در این متن به آن پرداختم، نوع خاصی از رگرسیونها است که تخصص آن روندشناسی و درک وجود و ماهیت روند دادهها است.
تحلیل Test for Linear Trend عددی نیز برای Slope به ما میدهد. این عدد هرچقدر بزرگتر باشد به معنای وجود روند قویتر در دادهها است. اعداد نزدیک به صفر برای Slope بیانگر عدم وجود روند در دادهها خواهد بود.
جهت محاسبه این شیب از کتاب زیر صفحات 952-940
Altman, D. G. 1991 Practical statistics for medical research. Chapman and Hall
و همچنین کتاب زیر صفحات ۲۱۳-۲۱۲ و ۲۲۰-۲۱۹ استفاده میشود.
Sheskin, D. 2011 Handbook of Parametric and Nonparametric Statistical Procedures, Fifth Edition 5th Edition, Chapman and Hall/CRC
کتاب بالا حدود 970 صفحه است و من فایل PDF آن را در همان لینک قرار دادهام. علاقمند بودید به این کتابها میتوانید مراجعه کنید.
همانگونه که بالاتر اشاره کردم نام این روش تحلیل
Test for Linear Trend
است. با این حال هنگامی که با نرمافزار Prism انجام میشود، علاوه بر روند خطی، روند غیرخطی (شاید بتوان نام آن را Test for Nonlinear Trend هم گذاشت) را هم بررسی میکند و به ازای هر کدام P-Trend جداگانه ارایه میکند.
من در لینک زیر سایت گراف پد سعی کردهام به این آزمون و معرفی سایر پارامترهای آن بپردازم.
https://graphpad.ir/test-for-linear-trend-prism/
آیا ابزار و روش تحلیلی وجود دارد که برای ما یک عدد تولید کند و ما با استفاده از آن عدد بگوییم، روند و گامهای بعدی دادهها صعودی – نزولی و یا فاقد روند (یکنواخت، ثابت) خواهد بود؟
پاسخ به این سوال مثبت است و میتوان از تحلیلی با نام آزمون روند خطی
Test for Linear Trend
نام برد.
این آزمون هنگامی که با نرمافزار Prism انجام میشود، علاوه بر بررسی وجود روند خطی، وجود روند غیرخطی را نیز تست میکند.
خب، حال بیایید به خروجیهای مهم Test for Linear Trend بپردازیم.
P-Trend
اولین یافته و شاید مهمترین آن، یک مقدار احتمال P-Value است. دوستانی که با مباحث آماری آشنا هستند میدانند در هر تست آماری P-Value ها به عنوان ابزار قضاوت آماری قرار میگیرند و به ما میگویند یافته معنادار است و یا معنادار نیست.
به عنوان مثال در یک تحلیل همبستگی، عدد به دست آمده از P-Value به ما میگوید ارتباط وجود دارد و یا وجود ندارد و یا در یک تحلیل مقایسهای به ما میگویند مشابهت و همانندی وجود دارد و یا وجود ندارد.
هنگامی که از
Test for Linear Trend
استفاده میکنیم به P-Value به دست آمده از این آزمون، اصطلاحاً P-Trend میگوییم.
عدد P-Trend همان عددی است که من در ابتدای متن از آن نام بردم. بیایید آن را بیشتر بشناسیم.
خوب است بدانیم P-Trend که همان P-Value سابق است، از جنس احتمال است و بنابراین به عنوان یک اندازه در بازه بین صفر و یک تعریف میشود. (دقت کنید هیچوقت صفر و یا یک به دست نمیآید) P نوشته شده در ابتدای نام آن به معنای Probability است.
این اتفاق بسیار مثبتی است. از دیدگاه آماری هر پارامتری که از جنس Probability باشد، قابلیت این را دارد که در چارچوب علمی قرار گیرد و وارد دنیای تئوری احتمال که خود بسیار گسترده است، شود. (در واقع ریشه تفاوت میان ریاضی و آمار همین است. ریاضیات به دنیای قطعیت و حتمیات میپردازد و آمار به دنیای احتمالات.)
گفتیم که P-Trend عددی احتمالی و در بازه صفر تا یک است. این عدد هرچقدر به یک نزدیکتر باشد به معنای عدم وجود روند در دادهها (پیشبینی ثابت و یکنواخت شدن) و هر چقدر به صفر نزدیکتر باشد به معنای ایجاد روند در دادهها (پیشبینی صعودی یا نزولی شدن) خواهد بود.
به عنوان مثال اگر P-Trend = 0.71 به دست بیاید، پیشبینی میکنیم دادهها با احتمال 71% فاقد Trend خواهند بود و با احتمال 29% روند به خود میگیرند. به همین ترتیب برای هر عدد دیگر به دست آمده از P-Trend میتوان چنین نتیجهای به دست آورد.
Slope
اصولاً ما وقتی نام شیب Slope را میشنویم به یاد مدلهای رگرسیونی و یا سری زمانی میافتیم. آزمون و روش تحلیل Test for Linear Trend که من در این متن به آن پرداختم، نوع خاصی از رگرسیونها است که تخصص آن روندشناسی و درک وجود و ماهیت روند دادهها است.
تحلیل Test for Linear Trend عددی نیز برای Slope به ما میدهد. این عدد هرچقدر بزرگتر باشد به معنای وجود روند قویتر در دادهها است. اعداد نزدیک به صفر برای Slope بیانگر عدم وجود روند در دادهها خواهد بود.
جهت محاسبه این شیب از کتاب زیر صفحات 952-940
Altman, D. G. 1991 Practical statistics for medical research. Chapman and Hall
و همچنین کتاب زیر صفحات ۲۱۳-۲۱۲ و ۲۲۰-۲۱۹ استفاده میشود.
Sheskin, D. 2011 Handbook of Parametric and Nonparametric Statistical Procedures, Fifth Edition 5th Edition, Chapman and Hall/CRC
کتاب بالا حدود 970 صفحه است و من فایل PDF آن را در همان لینک قرار دادهام. علاقمند بودید به این کتابها میتوانید مراجعه کنید.
همانگونه که بالاتر اشاره کردم نام این روش تحلیل
Test for Linear Trend
است. با این حال هنگامی که با نرمافزار Prism انجام میشود، علاوه بر روند خطی، روند غیرخطی (شاید بتوان نام آن را Test for Nonlinear Trend هم گذاشت) را هم بررسی میکند و به ازای هر کدام P-Trend جداگانه ارایه میکند.
من در لینک زیر سایت گراف پد سعی کردهام به این آزمون و معرفی سایر پارامترهای آن بپردازم.
https://graphpad.ir/test-for-linear-trend-prism/
یک سوال خوب این است که Moving Average (MA) را بر روی چه length (L) تنظیم کنیم؟ یک سوال کاملتر میتواند این باشد که اصولاً در مدلهای سری زمانی که سادهترین آن همین MA است، پارامترهای مدل را برای رسیدن به بهترین (کمترین خطا) بر روی چه عددی قرار دهیم؟
آشنا باشید مدلهای دیگری مانند Decomposition، Exponential Smoothing (همراه با انواع سهگانه آن)، Winters’ Method، SMA، AR، ARIMA و SARIMA دیگری نیز وجود دارند که در همهی آنها قرار دادن بهترین پارامترها که در نهایت ما را به بهترین مدل پیشبینی با کمترین خطا برسانند، مطرح است.
من در سایت گراف پد و بخش آموزشها برخی از این مدلهای سری زمانی را همراه با مثال و کار با نرمافزار Minitab توضیح دادهام. علاقمند بودید آنجا را ببینید.
برخی از آنها واقعاً جالب توجه هستند و به عنون مثال یکی از انواع مدل Exponential Smoothing دارای پارامتری به نام گاما است که به آن ضریب روند میگوییم. عدد به دست آمده برای این پارامتر که از آن به عنوان یک احتمال رخداد (P) نام میبرم، میتواند به ما در شناسایی دقیق نقاط ورود و خروج، کمک کند.
سوال این است که بهترین length در یک مدل MA چه عددی است. برای پاسخ به این سوال، ابتدا باید این نکته را بدانیم که انتخاب بهترین L در مدل MA، برای هر X ای باید جداگانه انجام شود. این X میتواند یک نماد بازار سهام، کریپتو و یا فارکس باشد. هر چیزی که در طول زمان Time حرکت دارد و امروزش با فردایش متفاوت است یا این لحظهاش با لحظه دیگر فرق میکند، مورد نظر ما است.
برای انتخاب و یافتن بهترین Length (L) (تاکید میکنم بهترین L به معنای یافتن بهترین و دقیقترین مدل پیشبینی است) مراحل زیر را انجام میدهیم.
1- ابتدا دادههای واقعی و مشاهده شده از کمیت X خود را به دست بیاورید. به عنوان مثال اگر میخواهید بر روی یک نماد بورسی یا BTC یا هر چیز دیگری کار کنید، ابتدا دادههای گذشته آن را در یک فایل اکسل فراهم کنید.
2- دادهها را به نرمافزار Minitab که در انجام تحلیلهای سری زمانی، مناسب و تاحدی ساده است، انتقال دهید.
3- در Minitab یک تحلیل میانگین متحرک یا همان Moving Average (MA) را انتخاب کنید. خوب است همین جا بگویم من در این متن سعی میکنم خیلی ساده حرف بزنم و از سادهترین مدل صحبت کنم. البته که همین مدل ساده، بسیار هم راهگشا است.
4- در Moving Average (MA) طول دلخواهی برای MA Length خود انتخاب کنید. پیشنهاد میکنم از عدد 1 شروع کنید. پس از آن از نرمافزار بخواهید خطاها یا همان باقیمانده Residuals مدل MA (1) را برای شما به دست بیاورد.
با انجام این کار در فایل دیتا، یک ستون اضافه میشود که در آن خطای مدل MA(1) به ازای هر تایم آمده است. یعنی شما به ازای هر تایم یک عدد واقعی، یک عدد پیشبینی شده و یک عدد خطای پیشبینی دارید. یعنی رابطهی زیر
E(t) = O(t) – P(t)
در این فرمول E یعنی خطا، O عدد واقعی و P عدد پیشبینی شده برای زمان t است.
واضح است که E میتواند مثبت و یا منفی باشد. خطای مثبت یعنی ما کمتر از مقدار واقعی پیشبینی کردهایم و خطای منفی یعنی ما بیشتر از مقدار واقعی پیشبینی کردهایم.
5- مرحله بالا را بار دیگر و این بار MA Length را برابر با 2 قرار دهید. این بار یک مدل MA(2) ساختهایم. یک ستون دیگر نیز به فایل دیتا اضافه شده که خطاهای مدل MA(2) به ازای هر تایم را نشان میدهد.
6- فرایند بالا را به تعداد دلخواه (هر چقدر بیشتر بهتر) تکرار میکنیم. مثلاً K بار تکرار کردهایم و در نهایت K ستون از خطاها در اختیار داریم. این کار را میتوانیم با برنامهنویسی در نرمافزار Minitab، سریعتر هم انجام دهیم.
7- خب، حال دوباره به سوال اصلی برگردیم. بهترین MA Length که بیشترین دقت و کمترین خطا را داشته باشد کدام است؟ برای پاسخ به این سوال باید ابزاری جهت قضاوت و انتخاب بهترین ستون از بین K ستون خطا داشته باشیم.
8- یک راه ساده و کاملاً غلط میانگین گرفتن از خطاهای هر ستون و بعد مقایسه میانگینها با یکدیگر است. ببینیم کدام ستون کمترین میانگین را دارد و آن را به عنوان بهترین ستون، یعنی همان L بهینه انتخاب کنیم.
واضح است که این کار غلط است. به دلیل اینکه خطاها مثبت و منفی هستند و میانگین گرفتن از آنها، باعث میشود که همدیگر را خنثی کنند. یعنی اگر در یک تایم به اندازه +5 خطا کنیم و در تایم دیگر -5 میانگین گرفتن باعث میشود که خطای ما صفر شود و ما فکر کنیم مدل ما خیلی خوب است و اصلاً خطا ندارد. (در پرانتز مینویسم که این کار با کمال تاسف یکی از دهها حقه آماری است که به شما نشان میدهد چقدر کار من خوب است و باید با تاسف بیشتری بنویسم که اساس فرمول و محاسبه شاخص بورس تهران نیز بر چنین حقهای قرار دارد. از این مطلب بگذریم که فعلاً موضوع حرف من نیست.)
گراف پد
رگرسیون حداقل مربعات معمولی Ordinary Least Squares regression (OLS)
رگرسیون حداقل مربعات معمولی مجموع خطا SSE مدل ماتریس ضرایب براورد پارامتر وارون پیش بینی عادی مینیمم Minimum پیش فرض نرمال هم خطی داده پرت واریانس Residual
9- هنگامی که میخواهیم ضرایب یک مدل رگرسیونی را براورد کنیم، بهترین روش برای براورد و یافتن ضرایب استفاده از تکنیک Ordinary Least Squares regression (OLS) است. من در این مقاله دربارهی این تکنیک توضیح دادهام.
ما در این تکنیک به براورد پارامترها بر مبنای خطاهای مدل میپردازیم. آن مدلی را هم بهترین میدانیم که مجموع توان دوم خطاها را مینیمم کند.
یعنی آن مدلی بهینه است که رابطهی زیر برای آن برقرار باشد
To Minimize Sum {E(t)^2}
10- این معادله به بیان ساده به معنای این است که از خطاها میانگین نگیرید، بلکه ابتدا آنها را به توان دو برسانید و سپس آنها را با هم جمع کنید. با انجام این کار، به عنوان همان مثال خطای +5 و -5 میانگین خطا صفر است (که خب گفتم غلط است و ما در واقعیت هر دو بار مرتکب خطای به اندازه 5 واحدی شدهایم) اما با استفاده از رابطهی بالا ما به اندازه 50 واحد خطا داشتهایم. 5^2 + 5^2
11- به این ترتیب بیایید برای هر کدام از ستونهای فایل دیتا که بیانگر خطای مدل MA بود، عدد مجموع توان دوم خطاها را به دست بیاورید. حال با خیال راحت میتوان گفت بهترین MA Length که نشاندهنده دقیقترین مدل پیشبینی است، آن ستونی است که مجموع توان دوم خطاهای آن از همه کمتر باشد.
اساس آنچه من در اینجا بیان کردم بر این واقعیت قرار دارد که گذشته چراغی است برای راه آینده. آنچه اعداد در زمانهای قبل طی کردهاند و به اینجا رسیدهاند، راهی است که آینده را به ما نشان میدهند.
گراف پد
رگرسیون حداقل مربعات معمولی Ordinary Least Squares regression (OLS)
رگرسیون حداقل مربعات معمولی مجموع خطا SSE مدل ماتریس ضرایب براورد پارامتر وارون پیش بینی عادی مینیمم Minimum پیش فرض نرمال هم خطی داده پرت واریانس Residual
#گمشده
فرض کنید یک نفر از خانه بیرون رفته و دیگر بازنگشته. او گمشده است.
چگونه او را پیدا میکنید؟
با خودش تماس میگیرید؟ آشنایان و دوستان را خبر میکنید؟ به پلیس اطلاع میدهید؟ به بیمارستانها و کلانتریها و ... سر میزنید؟ اطلاعیه و اعلامیه به دیوار میزنید؟ به روزنامهها و در اینترنت خبر میدهید؟میروید خیابان و فریاد و داد بیداد میکنید که ای مردم، بچهام، مادرم یا پدرم گمشده؟
چه میکنید؟
هدف نهایی آمار همین است. پیدا کردن گمشده، گمشدهها و آنی که نیست و غایب شده است.
این گمشده میتواند دادهای در گذشته و یا در آینده باشد. ما میخواهیم او را بیابیم. اکسیر زرگری و کیمیاگری آمار همین است. کشف گمشده گذشته و آینده.
به گرافهای تصویر پیوست نگاه کنید.
گراف a). در این گراف یک داده گمشده است. آن را با علامت ضربدر مشخص کردهام. هدف ما یافتن او است.
گراف b). از یک مدل رگرسیونی بهینه، بر روی دادههای موجود استفاده میکنیم. Y = f (X) مدل مدنظر ما خواهد بود. پیشبینی و Predict مدل، نقطه قرمز رنگ است. پیشبینی خوبی است، اما دقیقاً همان داده گمشده ما نیست. ما در پیدا کردن آن خطا داشتهایم.
گراف c). به نظر میرسد رگرسیون به تنهایی کافی نیست. سری زمانی Time Series نیز لازم است. پس مدل خود را به صورت
Y = f (X,t)
گسترش میدهیم.
مدل به دست آمده، پنج نقطه را برای ما برازش میدهد. در اینجا پیشبینیها دقیقتر است، منتهی ما به عنوان خواننده که از قبل نمیدانیم داده گمشده کدام است، با پنج نقطه برازش شده روبهرو هستیم.
مدل تعمیم رگرسیون و سری زمانی برای اینکه خطای پیشبینی خود در یافتن داده گمشده را کاهش دهد، تعداد نقاط برازش شده را بیشتر کرده است.
گراف d). به نظر میرسد به جای کار کردن با یک تابع f در مدل
Y = f (X,t)
چندین تابع خطی و غیرخطی دیگر را هم تست کنیم. در اینجا علاوه بر سری زمانی، چند f دیگر نیز به کار میبریم. نتیجه چندان قابل قبول نیست. تعدد f های تحلیل، حتی باعث شده است خطای ما بیشتر هم شود. به این نکته دقت کنید.
گراف e). دادههای موجود را به دو گروه تقسیم میکنیم. با دایره و مثبت آنها را مشخص کردهایم.
همان مدل تعمیم سری زمانی و رگرسیون یعنی Y = f (X,t) را یکبار دیگر و اینبار به ازای هر کدام از گروههای دایره و مثبت، برازش میدهیم.
نتیجه بهتر شده است. هر چند هنوز با چند گزینه روبهرو هستیم، با این حال خطای انتخاب کمتر شده است.
گراف f). مدل سری زمانی را کنار میگزاریم و دو مدل رگرسیونی جداگانه با استفاده از دادههای موجود، به ازای هر کدام از گروههای مشاهدات (دایره و مثبت) به دست میآوریم.
یعنی Y1 = f1 (X1) و Y2 = f2 (X2).
نتیجه به دست آمده تا حدی خوب است. مدل هم برای f1 (مشاهدات مثبت) و هم برای f2 (مشاهدات دایره) دادههای گمشده احتمالی را برازش میدهد.
در f1 مدل فکر میکند که دو نقطه مثبت که به دور آنها دایره قرمز رنگ کشیده شده و همچنین خط کوچک قرمز رنگ، محدوده احتمالی داده گمشده باشند.
واضح است که مدل f1 اشتباه میکند و برای ما که میدانیم داده گمشده کجاست (از روی گراف a) یک برازش غلط به حساب میآید. داده گمشده اصلا، در محدوده f1 و دادههای مثبت قرار ندارد.
در f2 مدل به دور چند دایره خط قرمز کشیده است. از نظر این مدل داده گمشده در همین حوالی باید قرار داشته باشد. از روی گراف a میدانیم که f2 تا حد زیادی پیشبینی درستی در یافتن داده گمشده داشته است.
خب، حال بیایید به اصل موضوع این متن ببردازیم.
من در اینجا از 5 مدل جهت براورد و پیشبینی داده گمشده استفاده کردم. خوب است واضح بگویم که اگر از 50 مدل یا 500 مدل دیگر هم استفاده میکردیم، نمیتوانستیم رابطه و مدلی را بیابیم که همیشه و قطعاً درست بگوید. بنابراین چند نکته مینویسم.
فرض کنید یک نفر از خانه بیرون رفته و دیگر بازنگشته. او گمشده است.
چگونه او را پیدا میکنید؟
با خودش تماس میگیرید؟ آشنایان و دوستان را خبر میکنید؟ به پلیس اطلاع میدهید؟ به بیمارستانها و کلانتریها و ... سر میزنید؟ اطلاعیه و اعلامیه به دیوار میزنید؟ به روزنامهها و در اینترنت خبر میدهید؟میروید خیابان و فریاد و داد بیداد میکنید که ای مردم، بچهام، مادرم یا پدرم گمشده؟
چه میکنید؟
هدف نهایی آمار همین است. پیدا کردن گمشده، گمشدهها و آنی که نیست و غایب شده است.
این گمشده میتواند دادهای در گذشته و یا در آینده باشد. ما میخواهیم او را بیابیم. اکسیر زرگری و کیمیاگری آمار همین است. کشف گمشده گذشته و آینده.
به گرافهای تصویر پیوست نگاه کنید.
گراف a). در این گراف یک داده گمشده است. آن را با علامت ضربدر مشخص کردهام. هدف ما یافتن او است.
گراف b). از یک مدل رگرسیونی بهینه، بر روی دادههای موجود استفاده میکنیم. Y = f (X) مدل مدنظر ما خواهد بود. پیشبینی و Predict مدل، نقطه قرمز رنگ است. پیشبینی خوبی است، اما دقیقاً همان داده گمشده ما نیست. ما در پیدا کردن آن خطا داشتهایم.
گراف c). به نظر میرسد رگرسیون به تنهایی کافی نیست. سری زمانی Time Series نیز لازم است. پس مدل خود را به صورت
Y = f (X,t)
گسترش میدهیم.
مدل به دست آمده، پنج نقطه را برای ما برازش میدهد. در اینجا پیشبینیها دقیقتر است، منتهی ما به عنوان خواننده که از قبل نمیدانیم داده گمشده کدام است، با پنج نقطه برازش شده روبهرو هستیم.
مدل تعمیم رگرسیون و سری زمانی برای اینکه خطای پیشبینی خود در یافتن داده گمشده را کاهش دهد، تعداد نقاط برازش شده را بیشتر کرده است.
گراف d). به نظر میرسد به جای کار کردن با یک تابع f در مدل
Y = f (X,t)
چندین تابع خطی و غیرخطی دیگر را هم تست کنیم. در اینجا علاوه بر سری زمانی، چند f دیگر نیز به کار میبریم. نتیجه چندان قابل قبول نیست. تعدد f های تحلیل، حتی باعث شده است خطای ما بیشتر هم شود. به این نکته دقت کنید.
گراف e). دادههای موجود را به دو گروه تقسیم میکنیم. با دایره و مثبت آنها را مشخص کردهایم.
همان مدل تعمیم سری زمانی و رگرسیون یعنی Y = f (X,t) را یکبار دیگر و اینبار به ازای هر کدام از گروههای دایره و مثبت، برازش میدهیم.
نتیجه بهتر شده است. هر چند هنوز با چند گزینه روبهرو هستیم، با این حال خطای انتخاب کمتر شده است.
گراف f). مدل سری زمانی را کنار میگزاریم و دو مدل رگرسیونی جداگانه با استفاده از دادههای موجود، به ازای هر کدام از گروههای مشاهدات (دایره و مثبت) به دست میآوریم.
یعنی Y1 = f1 (X1) و Y2 = f2 (X2).
نتیجه به دست آمده تا حدی خوب است. مدل هم برای f1 (مشاهدات مثبت) و هم برای f2 (مشاهدات دایره) دادههای گمشده احتمالی را برازش میدهد.
در f1 مدل فکر میکند که دو نقطه مثبت که به دور آنها دایره قرمز رنگ کشیده شده و همچنین خط کوچک قرمز رنگ، محدوده احتمالی داده گمشده باشند.
واضح است که مدل f1 اشتباه میکند و برای ما که میدانیم داده گمشده کجاست (از روی گراف a) یک برازش غلط به حساب میآید. داده گمشده اصلا، در محدوده f1 و دادههای مثبت قرار ندارد.
در f2 مدل به دور چند دایره خط قرمز کشیده است. از نظر این مدل داده گمشده در همین حوالی باید قرار داشته باشد. از روی گراف a میدانیم که f2 تا حد زیادی پیشبینی درستی در یافتن داده گمشده داشته است.
خب، حال بیایید به اصل موضوع این متن ببردازیم.
من در اینجا از 5 مدل جهت براورد و پیشبینی داده گمشده استفاده کردم. خوب است واضح بگویم که اگر از 50 مدل یا 500 مدل دیگر هم استفاده میکردیم، نمیتوانستیم رابطه و مدلی را بیابیم که همیشه و قطعاً درست بگوید. بنابراین چند نکته مینویسم.
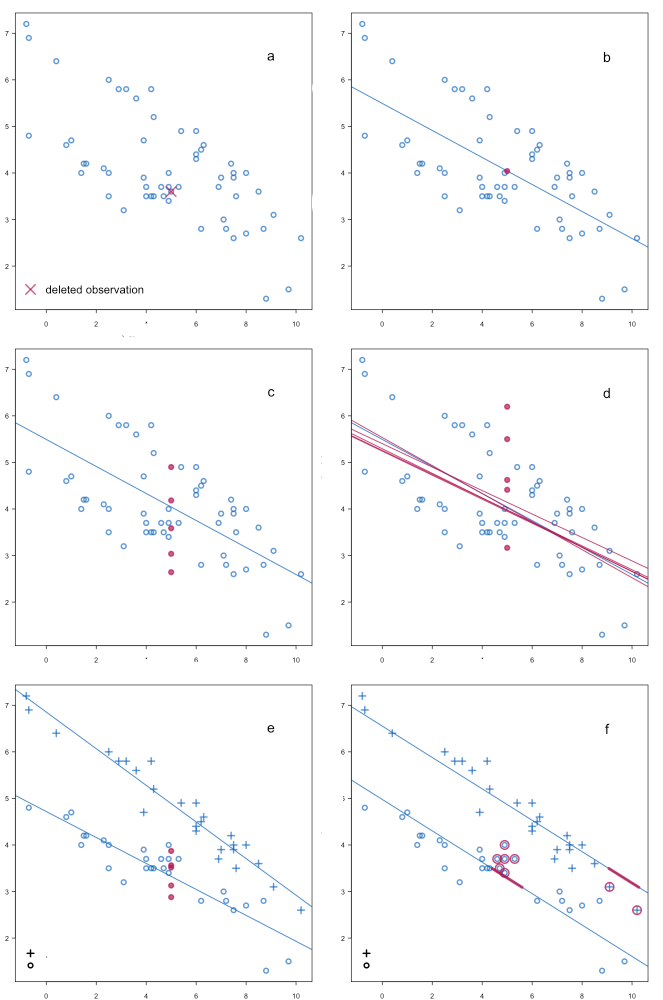{kind=link}
1- همهی این مدلها که من در اینجا برخی از خوبترینهای آنها را آوردم، محدودهای از پیشبینی درست همراه با مقداری خطا را خواهند داشت.
2- یافتن داده گمشدهای در گذشته و یا آینده یک فرایند احتمالی است. یعنی همهی مدلهای پیشبین دارای احتمال پیشبینی قطعا درست در بازه (0,1) هستند.
3- آمار در چند سال اخیر توانسته است مدلهایی بسازد که احتمال درستی آنها در بازه (0,1] قرار بگیرد. یعنی مدلی که همیشه قطعاً غلط است. اما همچنان از ساختن مدلی با احتمال درستی در بازه [0,1] ناتوان است. مدلی که همیشه قطعاً درست باشد، هنوز ساخته نشده است.
4- احتمالاً ساختن مدلی که همیشه 100 درصد درست باشد (p=1)، از رهگذر مدلهایی که همیشه قطعاً غلط هستند (p=0) ساخته خواهند شد. چیزهای زیادی در این باره هنوز نمیدانیم.
5- در سالهای متمادی رگرسیونها و بعد از آن انواع مدلهای سری زمانی که بسیاری از اندیکاتورها بر مبنای آنها ساخته شدهاند، مدلهای خوبی بودند و مورد استفاده قرار میگرفتند.
در چند سال اخیر کاربرد دقیق آنها زیر سوال رفته است. به جای آنها استفاده از فرایندهای گروهبندی و دستهبندی کردن دادهها (مثالهای ساده آن Cluster Analysis، PCA، PCR و ....) و پس از آن استفاده از مدلهای رگرسیونی و سری زمانی پیشنهاد میشود. مبنای این پیشنهاد، همهی دادهها را با یک چشم ندیدن، ساختن گروههای همانند در دادهها و مشابهسازی در دادهها است.
6- آنچه که آمار امروزه به آن رسیده است، رام کردن اسب سرکش تصادف و فرایندهای تصادفی است.
اغلب مدلهای پیشبین و یافتن دادههای گمشده (به خصوص آینده) دارای احتمال درستی در بازه (1, 0.5) هستند و p تابع توزیع برنولی آنها عددی بزرگتر از 0.5 است (p > 0.5).
برخی از مدلها که تعدادی از آنها را من در این متن آوردم دارای احتمال درستی با p > 0.9 هستند. این البته گام بلندی به جلو است، اما با هدف نهایی آمار که کشف قطعی آینده است، فاصله بسیار زیادی دارد.
2- یافتن داده گمشدهای در گذشته و یا آینده یک فرایند احتمالی است. یعنی همهی مدلهای پیشبین دارای احتمال پیشبینی قطعا درست در بازه (0,1) هستند.
3- آمار در چند سال اخیر توانسته است مدلهایی بسازد که احتمال درستی آنها در بازه (0,1] قرار بگیرد. یعنی مدلی که همیشه قطعاً غلط است. اما همچنان از ساختن مدلی با احتمال درستی در بازه [0,1] ناتوان است. مدلی که همیشه قطعاً درست باشد، هنوز ساخته نشده است.
4- احتمالاً ساختن مدلی که همیشه 100 درصد درست باشد (p=1)، از رهگذر مدلهایی که همیشه قطعاً غلط هستند (p=0) ساخته خواهند شد. چیزهای زیادی در این باره هنوز نمیدانیم.
5- در سالهای متمادی رگرسیونها و بعد از آن انواع مدلهای سری زمانی که بسیاری از اندیکاتورها بر مبنای آنها ساخته شدهاند، مدلهای خوبی بودند و مورد استفاده قرار میگرفتند.
در چند سال اخیر کاربرد دقیق آنها زیر سوال رفته است. به جای آنها استفاده از فرایندهای گروهبندی و دستهبندی کردن دادهها (مثالهای ساده آن Cluster Analysis، PCA، PCR و ....) و پس از آن استفاده از مدلهای رگرسیونی و سری زمانی پیشنهاد میشود. مبنای این پیشنهاد، همهی دادهها را با یک چشم ندیدن، ساختن گروههای همانند در دادهها و مشابهسازی در دادهها است.
6- آنچه که آمار امروزه به آن رسیده است، رام کردن اسب سرکش تصادف و فرایندهای تصادفی است.
اغلب مدلهای پیشبین و یافتن دادههای گمشده (به خصوص آینده) دارای احتمال درستی در بازه (1, 0.5) هستند و p تابع توزیع برنولی آنها عددی بزرگتر از 0.5 است (p > 0.5).
برخی از مدلها که تعدادی از آنها را من در این متن آوردم دارای احتمال درستی با p > 0.9 هستند. این البته گام بلندی به جلو است، اما با هدف نهایی آمار که کشف قطعی آینده است، فاصله بسیار زیادی دارد.
همین تلگرام. تعداد دفعاتی که شما در طول روز تلگرام گوشی موبایل خود را چک میکنید، دارای توزیع پواسن است.
تعداد دفعاتی که یک دانشجو و یا سرباز در طول سال از دانشگاه یا پادگان به خانه برمیگردد، نیز توزیع پواسن دارد. در اینجا هر فرد برای خودش یک توزیع پواسن دارد.
اصولاً بسیاری از کارهای روزمره که با تعداد و فراوانی تکرار روبهرو هستند دارای نظم ریاضی با نام پواسن هستند.
کمی بزرگتر تعداد زمین لرزهها در یک منطقه، تعداد محصولات خراب در یک خط تولید کارخانه، تعداد تصادفات در یک جاده و عمومیتر تعداد بسیاری از رویدادهای قابل شمارش، دارای توزیع پواسن هستند.
از ویژگیهای مهم توزیع پواسن، برابر بودن میانگین و واریانس این توزیع است که در کمتر نظم ریاضی دیگری میتوان مشاهده کرد.
دربارهی فرمول و معادله این توزیع و پارامتر لاندا (Lambda) آن که همان میانگین و واریانس براورد شده توزیع پواسن است، زیاد میتوان صحبت کرد. من فعلاً از آن صرفنظر میکنم. علاقمند بودید درباره توزیع پواسن (Poisson Distribution) سرچ کنید.
موضوع بحث من در اینجا توزیع پواسن نیست، بلکه چیز دیگری است.
دکتر احمد پارسان که استاد مشاوره من در دوره کارشناسی ارشد دانشگاه تهران بود، کتابی دارد با نام مبانی آمار ریاضی. این کتاب همراه با کتاب مبانی احتمال نوشته شلدون راس را میتوان پایه و اساس فهم تئوریک آمار دانست. هر دو کتابهای سختی هستند و تمام کتاب اثبات و فرمول است. منتهی خواندن دقیق آنها برای هر فردی که میخواهد آمار یاد بگیرد، ضروری است.
در صفحات ابتدایی کتاب مبانی آمار ریاضی اثبات میشود که چنانچه پدیده و رخدادی دارای توزیع پواسن باشد، فاصله زمانی بین هر دو رخداد متوالی آن دارای توزیع دیگری با نام توزیع نمایی خواهد بود.
جالب توجه است که میانگین این توزیع نمایی، وارون میانگین توزیع پواسن، یعنی یک تقسیم بر Lambda است.
وارد شدن به دنیای بزرگ توزیعهای آماری و پس از آن و البته بزرگتر از آن روابط بین توزیعهای آماری بسیار جالب و زیربنای فهم دقیق از آمار و کار با مدلها و نرمافزارهای آماری میباشد.
یکبار دیگر این تعریف را مرور کنید. چنانچه اثبات شود پدیدهای دارای توزیع پواسن است، فاصله زمانی بین هر دو رخداد متوالی آن پدیده، توزیع نمایی دارد.
یعنی همان چک کردن تلگرام گوشی موبایل، فاصله زمانی هر دو بار چک کردن، یک توزیع نمایی دارد که گفتم هر فرد توزیع نمایی مربوط به خودش را هم دارد.
به عنوان مثال وقتی ثابت میشود که تعداد زمین لرزهها توزیع پواسن دارد، فاصله بین هر دو زمین لرزه متوالی توزیع نمایی خواهد داشت. این مسئله یافته مهمی در پیشبینیها مورد استفاده قرار میگیرد.
حال بیایید این تئوریها را با تئوری احتمال ترکیب کنیم. من اسم آن را هر چقدر دیرتر، زودتر میگذارم.
یعنی چه؟
تعداد رخداد پدیدهای توزیع پواسن است. پس فاصله بین هر دو رخداد متوالی توزیع نمایی است. حال اینجا احتمال وارد میشود. رخداد بعدی کی اتفاق میافتد؟
پاسخ همان است که نوشتم. هر چقدر دیرتر رخ دهد، یعنی فاصله زمانی بیشتری بگذرد، شانس و احتمال رخداد بیشتر میشود.
مثلاً همان بازگشت دانشجو یا سرباز به خانه را در نظر بگیرید. تعداد دفعات بازگشت به خانه پواسن است، فاصله زمانی بین هر دو مراجعه، نمایی است. حال والدین میگویند او دفعه بعد کی میآید؟
پاسخ از نظر تئوری آماری این است که او هر چقدر دیرتر بیاید، احتمال بازگشت او بیشتر میشود. یعنی اگر امروز جمعه است و او نیامده، احتمال آمدن او شنبه بیشتر از جمعه میشود و یکشنبه بیشتر از شنبه و به همین ترتیب برای روزهای آینده تا روزی که او میآید و احتمال برابر با یک میشود (P = 1).
به این نکته توجه کنید که این تئوری بر مبنای دو رویداد متوالی است. یعنی رویداد بعدی قطعاً رخ میدهد.
حال فرض کنید شما در یک بازار فیوچرز کار میکنید. تعداد دفعات باز کردن پوزیشن دارای توزیع پواسن است و فاصله زمانی بین باز کردن هر دو پوزیشن متوالی توزیع نمایی.
میدانیم که احتمال سود در هر پوزیشن، یک توزیع برنولی با احتمال P است.
در همان روابط بین توزیعها اثبات میشود که اگر X توزیع پواسن داشته باشد، توزیع احتمال شرطی
X | Sum (X_i) = Y = n
یک توزیع برنولی با احتمال P = 1/n است. یعنی هر چقدر n بیشتر باشد، P کمتر میشود.
خب، اینها یعنی چه؟
یعنی اینکه شما هر چقدر تعداد X های دارای توزیع پواسن را افزایش دهید، یعنی فاصله زمانی بین هر دو رخداد متوالی X را کاهش دادهاید، پس میانگین توزیع نمایی خود را کوچک کردهاید. یعنی در حال کاهش احتمال سود در پوزیشن بعدی هستید.
این مطلب به وضوح نشان میدهد در یک محیط مالی فیوچرز، افزایش فراوانی تعداد باز کردن پوزیشنها، شانس سود در پوزیشنهای بعدی را کاهش و احتمال لیکوئید شدن را افزایش میدهد.
تعداد دفعاتی که یک دانشجو و یا سرباز در طول سال از دانشگاه یا پادگان به خانه برمیگردد، نیز توزیع پواسن دارد. در اینجا هر فرد برای خودش یک توزیع پواسن دارد.
اصولاً بسیاری از کارهای روزمره که با تعداد و فراوانی تکرار روبهرو هستند دارای نظم ریاضی با نام پواسن هستند.
کمی بزرگتر تعداد زمین لرزهها در یک منطقه، تعداد محصولات خراب در یک خط تولید کارخانه، تعداد تصادفات در یک جاده و عمومیتر تعداد بسیاری از رویدادهای قابل شمارش، دارای توزیع پواسن هستند.
از ویژگیهای مهم توزیع پواسن، برابر بودن میانگین و واریانس این توزیع است که در کمتر نظم ریاضی دیگری میتوان مشاهده کرد.
دربارهی فرمول و معادله این توزیع و پارامتر لاندا (Lambda) آن که همان میانگین و واریانس براورد شده توزیع پواسن است، زیاد میتوان صحبت کرد. من فعلاً از آن صرفنظر میکنم. علاقمند بودید درباره توزیع پواسن (Poisson Distribution) سرچ کنید.
موضوع بحث من در اینجا توزیع پواسن نیست، بلکه چیز دیگری است.
دکتر احمد پارسان که استاد مشاوره من در دوره کارشناسی ارشد دانشگاه تهران بود، کتابی دارد با نام مبانی آمار ریاضی. این کتاب همراه با کتاب مبانی احتمال نوشته شلدون راس را میتوان پایه و اساس فهم تئوریک آمار دانست. هر دو کتابهای سختی هستند و تمام کتاب اثبات و فرمول است. منتهی خواندن دقیق آنها برای هر فردی که میخواهد آمار یاد بگیرد، ضروری است.
در صفحات ابتدایی کتاب مبانی آمار ریاضی اثبات میشود که چنانچه پدیده و رخدادی دارای توزیع پواسن باشد، فاصله زمانی بین هر دو رخداد متوالی آن دارای توزیع دیگری با نام توزیع نمایی خواهد بود.
جالب توجه است که میانگین این توزیع نمایی، وارون میانگین توزیع پواسن، یعنی یک تقسیم بر Lambda است.
وارد شدن به دنیای بزرگ توزیعهای آماری و پس از آن و البته بزرگتر از آن روابط بین توزیعهای آماری بسیار جالب و زیربنای فهم دقیق از آمار و کار با مدلها و نرمافزارهای آماری میباشد.
یکبار دیگر این تعریف را مرور کنید. چنانچه اثبات شود پدیدهای دارای توزیع پواسن است، فاصله زمانی بین هر دو رخداد متوالی آن پدیده، توزیع نمایی دارد.
یعنی همان چک کردن تلگرام گوشی موبایل، فاصله زمانی هر دو بار چک کردن، یک توزیع نمایی دارد که گفتم هر فرد توزیع نمایی مربوط به خودش را هم دارد.
به عنوان مثال وقتی ثابت میشود که تعداد زمین لرزهها توزیع پواسن دارد، فاصله بین هر دو زمین لرزه متوالی توزیع نمایی خواهد داشت. این مسئله یافته مهمی در پیشبینیها مورد استفاده قرار میگیرد.
حال بیایید این تئوریها را با تئوری احتمال ترکیب کنیم. من اسم آن را هر چقدر دیرتر، زودتر میگذارم.
یعنی چه؟
تعداد رخداد پدیدهای توزیع پواسن است. پس فاصله بین هر دو رخداد متوالی توزیع نمایی است. حال اینجا احتمال وارد میشود. رخداد بعدی کی اتفاق میافتد؟
پاسخ همان است که نوشتم. هر چقدر دیرتر رخ دهد، یعنی فاصله زمانی بیشتری بگذرد، شانس و احتمال رخداد بیشتر میشود.
مثلاً همان بازگشت دانشجو یا سرباز به خانه را در نظر بگیرید. تعداد دفعات بازگشت به خانه پواسن است، فاصله زمانی بین هر دو مراجعه، نمایی است. حال والدین میگویند او دفعه بعد کی میآید؟
پاسخ از نظر تئوری آماری این است که او هر چقدر دیرتر بیاید، احتمال بازگشت او بیشتر میشود. یعنی اگر امروز جمعه است و او نیامده، احتمال آمدن او شنبه بیشتر از جمعه میشود و یکشنبه بیشتر از شنبه و به همین ترتیب برای روزهای آینده تا روزی که او میآید و احتمال برابر با یک میشود (P = 1).
به این نکته توجه کنید که این تئوری بر مبنای دو رویداد متوالی است. یعنی رویداد بعدی قطعاً رخ میدهد.
حال فرض کنید شما در یک بازار فیوچرز کار میکنید. تعداد دفعات باز کردن پوزیشن دارای توزیع پواسن است و فاصله زمانی بین باز کردن هر دو پوزیشن متوالی توزیع نمایی.
میدانیم که احتمال سود در هر پوزیشن، یک توزیع برنولی با احتمال P است.
در همان روابط بین توزیعها اثبات میشود که اگر X توزیع پواسن داشته باشد، توزیع احتمال شرطی
X | Sum (X_i) = Y = n
یک توزیع برنولی با احتمال P = 1/n است. یعنی هر چقدر n بیشتر باشد، P کمتر میشود.
خب، اینها یعنی چه؟
یعنی اینکه شما هر چقدر تعداد X های دارای توزیع پواسن را افزایش دهید، یعنی فاصله زمانی بین هر دو رخداد متوالی X را کاهش دادهاید، پس میانگین توزیع نمایی خود را کوچک کردهاید. یعنی در حال کاهش احتمال سود در پوزیشن بعدی هستید.
این مطلب به وضوح نشان میدهد در یک محیط مالی فیوچرز، افزایش فراوانی تعداد باز کردن پوزیشنها، شانس سود در پوزیشنهای بعدی را کاهش و احتمال لیکوئید شدن را افزایش میدهد.
به زبان سادهتر یعنی اینکه چنانچه در یک تایم خاص تعدد باز کردن پوزیشن داشته باشید، احتمال لیکویید شدن شما به شدت افزایش پیدا می کند.
به بیان دیگر تعدد و فراوانی تعداد معاملات فیوچرز در یک بازه ثابت، شانس سود شما را بیشتر نمیکند که هیچ، بلکه شانس لیکوئید شدن را افزایش میدهد.
مثلاً از صبح تا شب بنشینید و به امید کسب سود دهها پوزیشن را باز و بسته کنید، در نهایت با احتمال بسیار فراوان شما شب یا حتی قبل از شب لیکوئید شدهاید.
این مطلب و تئوری آماری که من در بالا به آن اشاره کردم، در نهان خود ایده اثبات شدهای را دارد که بهبود کیفیت زندگی (هر فرد به راهی که خودش میداند)، دوری از استرس، آرامش، تعداد کم باز کردن پوزیشنها در فاصله زمانی زیاد، در بهبود معامله و کسب سود، تاثیر مثبت و معناداری دارد.
بنابراین وقتی یک پوزیشن را باز میکنید و آن را میبندید، به سرعت پوزیشن دیگری را باز نکنید. استراحت کنید، قدم بزنید و به چیزهای دیگری فکر کنید، کیفیت زندگی خود را بهبود دهید و چند روز دیگر باز گردید.
یعنی T توزیع نمایی که همان فاصله زمانی بین دو رخداد متوالی (در اینجا رخداد به معنای باز کردن پوزیشن فیوچرز است) را افزایش دهید. با افزایش آن احتمال سود در پوزیشن باز شده بعدی را افزایش میدهید.
تا آنجا که میدانم و خواندهام این یک تکنیک موفق در نویسندگان بزرگ بوده است. آنها داستانی را که در حال نوشتن آن بودند در اوج رها میکردند، به زندگی خود میپرداختند، چند روز بعد باز میگشتند و دوباره مینوشتند.
به بیان دیگر تعدد و فراوانی تعداد معاملات فیوچرز در یک بازه ثابت، شانس سود شما را بیشتر نمیکند که هیچ، بلکه شانس لیکوئید شدن را افزایش میدهد.
مثلاً از صبح تا شب بنشینید و به امید کسب سود دهها پوزیشن را باز و بسته کنید، در نهایت با احتمال بسیار فراوان شما شب یا حتی قبل از شب لیکوئید شدهاید.
این مطلب و تئوری آماری که من در بالا به آن اشاره کردم، در نهان خود ایده اثبات شدهای را دارد که بهبود کیفیت زندگی (هر فرد به راهی که خودش میداند)، دوری از استرس، آرامش، تعداد کم باز کردن پوزیشنها در فاصله زمانی زیاد، در بهبود معامله و کسب سود، تاثیر مثبت و معناداری دارد.
بنابراین وقتی یک پوزیشن را باز میکنید و آن را میبندید، به سرعت پوزیشن دیگری را باز نکنید. استراحت کنید، قدم بزنید و به چیزهای دیگری فکر کنید، کیفیت زندگی خود را بهبود دهید و چند روز دیگر باز گردید.
یعنی T توزیع نمایی که همان فاصله زمانی بین دو رخداد متوالی (در اینجا رخداد به معنای باز کردن پوزیشن فیوچرز است) را افزایش دهید. با افزایش آن احتمال سود در پوزیشن باز شده بعدی را افزایش میدهید.
تا آنجا که میدانم و خواندهام این یک تکنیک موفق در نویسندگان بزرگ بوده است. آنها داستانی را که در حال نوشتن آن بودند در اوج رها میکردند، به زندگی خود میپرداختند، چند روز بعد باز میگشتند و دوباره مینوشتند.
درباره متن بالا و مطالبی که درباره توزیع پواسن و نمایی نوشتم، چند سوال از من پرسیده شده بود. در چند نکته توضیح میدهم.
1- آنچه که من اشاره کردم و مثال آوردم، به وضوح مربوط به یک بازار فیوچرز با مشخصات مخصوص به خودش است.
2- یک بازار اسپات به سختی میتواند پیشفرضهای توزیع پواسن و پس از آن توزیع نمایی را پاس کند. برابر بودن امید ریاضی E(X) و واریانس Var (X) در توزیع پواسن، ویژگی مهمی است که در اسپات، تایید آن اما و اگر فراوان دارد.
3- اما بازار بورس تهران. این یکی را حتی اگر بتوان یک بازار اسپات دانست، اما قطعاً توزیع پواسن ندارد. بورس تهران یک بازار تبدیل شده به توزیعهای تصادفی (Random Distribution) است که خیلی بخواهیم اغماض کنیم و نگوییم تصادفی است، بلکه یک توزیع با پارامتر آزاد به حساب میآید و در محدوده آمار ناپارامتری قرار میگیرد.
پواسن، نمایی، نرمال، یکنواخت و ... از جمله توزیعهای پارامتری و دارای نظم و رابطه ریاضی مشخص و فرمولبندی شده هستند.
4- وقتی بازار بورس تهران، توزیع پواسن ندارد بنابراین فاصله زمانی بین دو رخداد متوالی در آن (در اینجا یعنی باز کردن یک معامله خرید) هم فاقد توزیع نمایی است.
در نتیجه افزایش و یا کاهش T فاصله زمانی بین دو رویداد، تاثیر معناداری در افزایش یا کاهش احتمال سود نخواهد داشت. هر چند باید شانس کمی بیشتری را در افزایش T مشاهده کرد. یعنی طولانی کردن فاصله زمانی بین دو رخداد، میتواند کمی بیشتر احتمال موفقیت را افزایش دهد.
با این حال این ایده، احتمالی و شبیهسازی شده است و نظم ریاضی مانند آنچه در بازار فیوچرز گفتم را ندارد.
بنابراین به زبان ساده آن بخش علم را که به توزیعهای پارامتری و مدلهای ریاضی مربوط میشود، به بازار بورس تهران ارتباط ندهید.
1- آنچه که من اشاره کردم و مثال آوردم، به وضوح مربوط به یک بازار فیوچرز با مشخصات مخصوص به خودش است.
2- یک بازار اسپات به سختی میتواند پیشفرضهای توزیع پواسن و پس از آن توزیع نمایی را پاس کند. برابر بودن امید ریاضی E(X) و واریانس Var (X) در توزیع پواسن، ویژگی مهمی است که در اسپات، تایید آن اما و اگر فراوان دارد.
3- اما بازار بورس تهران. این یکی را حتی اگر بتوان یک بازار اسپات دانست، اما قطعاً توزیع پواسن ندارد. بورس تهران یک بازار تبدیل شده به توزیعهای تصادفی (Random Distribution) است که خیلی بخواهیم اغماض کنیم و نگوییم تصادفی است، بلکه یک توزیع با پارامتر آزاد به حساب میآید و در محدوده آمار ناپارامتری قرار میگیرد.
پواسن، نمایی، نرمال، یکنواخت و ... از جمله توزیعهای پارامتری و دارای نظم و رابطه ریاضی مشخص و فرمولبندی شده هستند.
4- وقتی بازار بورس تهران، توزیع پواسن ندارد بنابراین فاصله زمانی بین دو رخداد متوالی در آن (در اینجا یعنی باز کردن یک معامله خرید) هم فاقد توزیع نمایی است.
در نتیجه افزایش و یا کاهش T فاصله زمانی بین دو رویداد، تاثیر معناداری در افزایش یا کاهش احتمال سود نخواهد داشت. هر چند باید شانس کمی بیشتری را در افزایش T مشاهده کرد. یعنی طولانی کردن فاصله زمانی بین دو رخداد، میتواند کمی بیشتر احتمال موفقیت را افزایش دهد.
با این حال این ایده، احتمالی و شبیهسازی شده است و نظم ریاضی مانند آنچه در بازار فیوچرز گفتم را ندارد.
بنابراین به زبان ساده آن بخش علم را که به توزیعهای پارامتری و مدلهای ریاضی مربوط میشود، به بازار بورس تهران ارتباط ندهید.
#همین_او
هر روز دهها نفر را میبینیم، آشنا یا غیرآشنا، مرد و زن. دختر یا پسر، پیر یا جوان. فرقی نمیکند. با برخی حرف میزنیم، ارتباط برقرار میکنیم و با برخی هم فقط از کنار آنها رد میشویم. در خیابان چشممان به یک نفر میافتد، در تاکسی، اتوبوس و یا مترو کنار یک نفر مینشینیم و یا میایستیم.
در محل کار، پارک یا یک جلسه کنار یک نفر مینشینیم. او را میشناسیم یا نمیشناسیم مهم نیست. اینجا فقط یک چیز مهم است، چشم ما یک نفر را میبیند، شاید با او حرف بزنیم، شاید هم کنار او بنشینیم.
پس سه چیز مهم اینجا وجود دارد. چشمی برای دیدن، زبانی برای حرف زدن و کناری برای نشستن یا ایستادن.
حال سوال اصلی این است.
چقدر احتمال دارد (احتمال یک اندازه قابل مشاهده است) فردی که ما او را دیدهایم (هر کجا)، شاید با او حرف زدهایم (حتی در حد یک یا چند کلمه) و شاید کنار او نشستهایم (حتی در فاصله بین دو ایستگاه اتوبوس) معشوقه، رویا و حسرت یک نفر دیگری بوده است که هرگز به او نرسیده.
در واقع P احتمال اینکه فردی که چشم ما به چشم او میافتد، کنار او نشستهایم و یا با او کلامی صحبت کردهایم، آرزوی دست نیافتنی و رویای امیدوار به دیدن فرد دیگری بوده باشد؟
سوال ساده است. آدمی که از کنار ما میگذرد و یا به اقتضای زمان و مکان دمی کنار ما است، اندازه احتمال محبوبه و معشوقه بودنش چقدر است؟ چقدر احتمال دارد همین دمی که ما خواسته و ناخواسته کنار او قرار گرفتهایم، آرزوی فرد دیگری است که این محبوبه و معشوقهاش را فقط ببیند، کنار او بنشیند و رویایش این بوده با او حرف بزند؟
ابتدا هم گفتم، مرد و زن، پیر و جوان، فقیر و ثروتمند، معروف و غیر معروف، شهری یا روستایی، دختر یا پسر، فرقی ندارد. من از انسان حرف میزنم.
پاسخ به این سوال در رگرسیون پروبیت Probit Regression که مدل پروبیت نیز نامیده میشود، قرار دارد. این رگرسیون، برای مدلسازی کمیتهای وابسته Dependent Variable دوگانه یا باینری استفاده میشود. با این تفاوت که در در رگرسیون پروبیت، تابع توزیع نرمال استاندارد تجمعی برای مدلسازی استفاده میشود، یعنی فرض میکنیم
P (Y=1 | X)
= P (Y=1 | B_0 + B_i X_i)
= Phi (B_0 + B_i X_i)
به معنای اینکه برای به دست آوردن احتمال رخداد پیشامد مورد نظر (Y=1) از یک احتمال شرطی بر روی X ها استفاده میکنیم. این احتمال شرطی نیز به صورت یک مدل رگرسیونی با استفاده از توزیع نرمال تجمعی تعریف میشود.
من در این متن قصد ندارم به آموزش رگرسیوم پروبیت بپردازم، در این زمینه علاقمند بودید لینک طراحی مدل رگرسیون پروبیت Probit Regression با نرم افزار SPSS در سایت گراف پد را مطالعه کنید.
اجازه دهید من به سوال اصلی این متن و پاسخ به آن بپردازم.
در یک مطالعه بر روی ۱۹ هزار نفر افراد ۳۵ تا ۷۵ ساله که دادههای آن برایم ارسال شده بود، حدود ۸۴.۷ درصد افراد عشق و دوست داشتن (حداقل به یک نفر) را در زندگی خود تجربه کردهاند.
حدود ۷۰.۱ درصد این افراد نیز به آنکه دوستش داشتهاند نرسیدهاند و ۵۰.۹ درصد این افراد همچنان در فکر، خیال و رویای دیدن، حرف زدن و نشستن کنار آنکه دوستش داشتهاند، زندگی میکنند.
عدد ۵۰.۹ درصد یک عدد بینالمللی است. به نظر من این عدد به دلایل اجتماعی، فرهنگی و آنچه در جامعه ایرانی بر سر افراد ۳۵ تا ۷۵ ساله گذشته است، حتی بیشتر نیز هست.
در قدیمیها به دلیل نبود تکنولوژی که خبری از محبوبشان بگیرند یا با او به هر طریقی حرف بزنند و یا در افراد متولد دهه ۵۰ و ۶۰ به دلیل فضای بستهتر جامعه ایرانی، به ویژه برای دختران.
بنابراین خیلی ساده.
با احتمال نزدیک به ۵۱ درصد، فردی که کنار او مینشینید، با او حرف میزنید و یا چشمان او را میبینید، آرزوی دست نیافتنی، حسرت بر دل مانده و رویای زندگی فرد دیگری است.
بنابراین با این محبوبهی معشوقه هر طور که فکر میکنید بهتر و درستتر است، رفتار کنید، حرف بزنید و چشمان او را ببینید.
هر روز دهها نفر را میبینیم، آشنا یا غیرآشنا، مرد و زن. دختر یا پسر، پیر یا جوان. فرقی نمیکند. با برخی حرف میزنیم، ارتباط برقرار میکنیم و با برخی هم فقط از کنار آنها رد میشویم. در خیابان چشممان به یک نفر میافتد، در تاکسی، اتوبوس و یا مترو کنار یک نفر مینشینیم و یا میایستیم.
در محل کار، پارک یا یک جلسه کنار یک نفر مینشینیم. او را میشناسیم یا نمیشناسیم مهم نیست. اینجا فقط یک چیز مهم است، چشم ما یک نفر را میبیند، شاید با او حرف بزنیم، شاید هم کنار او بنشینیم.
پس سه چیز مهم اینجا وجود دارد. چشمی برای دیدن، زبانی برای حرف زدن و کناری برای نشستن یا ایستادن.
حال سوال اصلی این است.
چقدر احتمال دارد (احتمال یک اندازه قابل مشاهده است) فردی که ما او را دیدهایم (هر کجا)، شاید با او حرف زدهایم (حتی در حد یک یا چند کلمه) و شاید کنار او نشستهایم (حتی در فاصله بین دو ایستگاه اتوبوس) معشوقه، رویا و حسرت یک نفر دیگری بوده است که هرگز به او نرسیده.
در واقع P احتمال اینکه فردی که چشم ما به چشم او میافتد، کنار او نشستهایم و یا با او کلامی صحبت کردهایم، آرزوی دست نیافتنی و رویای امیدوار به دیدن فرد دیگری بوده باشد؟
سوال ساده است. آدمی که از کنار ما میگذرد و یا به اقتضای زمان و مکان دمی کنار ما است، اندازه احتمال محبوبه و معشوقه بودنش چقدر است؟ چقدر احتمال دارد همین دمی که ما خواسته و ناخواسته کنار او قرار گرفتهایم، آرزوی فرد دیگری است که این محبوبه و معشوقهاش را فقط ببیند، کنار او بنشیند و رویایش این بوده با او حرف بزند؟
ابتدا هم گفتم، مرد و زن، پیر و جوان، فقیر و ثروتمند، معروف و غیر معروف، شهری یا روستایی، دختر یا پسر، فرقی ندارد. من از انسان حرف میزنم.
پاسخ به این سوال در رگرسیون پروبیت Probit Regression که مدل پروبیت نیز نامیده میشود، قرار دارد. این رگرسیون، برای مدلسازی کمیتهای وابسته Dependent Variable دوگانه یا باینری استفاده میشود. با این تفاوت که در در رگرسیون پروبیت، تابع توزیع نرمال استاندارد تجمعی برای مدلسازی استفاده میشود، یعنی فرض میکنیم
P (Y=1 | X)
= P (Y=1 | B_0 + B_i X_i)
= Phi (B_0 + B_i X_i)
به معنای اینکه برای به دست آوردن احتمال رخداد پیشامد مورد نظر (Y=1) از یک احتمال شرطی بر روی X ها استفاده میکنیم. این احتمال شرطی نیز به صورت یک مدل رگرسیونی با استفاده از توزیع نرمال تجمعی تعریف میشود.
من در این متن قصد ندارم به آموزش رگرسیوم پروبیت بپردازم، در این زمینه علاقمند بودید لینک طراحی مدل رگرسیون پروبیت Probit Regression با نرم افزار SPSS در سایت گراف پد را مطالعه کنید.
اجازه دهید من به سوال اصلی این متن و پاسخ به آن بپردازم.
در یک مطالعه بر روی ۱۹ هزار نفر افراد ۳۵ تا ۷۵ ساله که دادههای آن برایم ارسال شده بود، حدود ۸۴.۷ درصد افراد عشق و دوست داشتن (حداقل به یک نفر) را در زندگی خود تجربه کردهاند.
حدود ۷۰.۱ درصد این افراد نیز به آنکه دوستش داشتهاند نرسیدهاند و ۵۰.۹ درصد این افراد همچنان در فکر، خیال و رویای دیدن، حرف زدن و نشستن کنار آنکه دوستش داشتهاند، زندگی میکنند.
عدد ۵۰.۹ درصد یک عدد بینالمللی است. به نظر من این عدد به دلایل اجتماعی، فرهنگی و آنچه در جامعه ایرانی بر سر افراد ۳۵ تا ۷۵ ساله گذشته است، حتی بیشتر نیز هست.
در قدیمیها به دلیل نبود تکنولوژی که خبری از محبوبشان بگیرند یا با او به هر طریقی حرف بزنند و یا در افراد متولد دهه ۵۰ و ۶۰ به دلیل فضای بستهتر جامعه ایرانی، به ویژه برای دختران.
بنابراین خیلی ساده.
با احتمال نزدیک به ۵۱ درصد، فردی که کنار او مینشینید، با او حرف میزنید و یا چشمان او را میبینید، آرزوی دست نیافتنی، حسرت بر دل مانده و رویای زندگی فرد دیگری است.
بنابراین با این محبوبهی معشوقه هر طور که فکر میکنید بهتر و درستتر است، رفتار کنید، حرف بزنید و چشمان او را ببینید.
با ترند و ضریب بتا که هر نماد در طول زمان حرکت میکند آشنا هستیم. میدانیم که ضریب بتا از یک مدل رگرسیون خطی گذشتهنگر به صورت زیر ساخته میشود.
Y = b_0 + b_1X
در این مدل ساده، Y همان قیمت و X زمان است. بنابراین مدل بالا را به صورت درستتر میتوان به صورت زیر نوشت.
Y = b_0 + b_1t
همچنین b نیز همان ضریب بتا که میتواند عددی از منفی تا مثبت بینهایت باشد و محدودیتی ندارد.
نکته مهمی که وجود دارد این است که این یک مدل رگرسیونی گذشتهنگر است. یعنی ما بر مبنای دادههای قبلی به برازش و یافتن یک مدل میپردازیم.
از این مدل گذشته نگر نیز انتظار داریم، مبنایی برای رفتار حرکت قیمت در آینده باشد. البته واضح است که این انتظار نمیتواند همواره درست باشد و دلیلی ندارد آنچه در گذشته اتفاق افتاده، مسیری برای آینده نیز باشد.
موضوعی که من میخواهم در این متن به آن اشاره کنم این است که چگونه میتوان یک تئوری و رابطه ریاضی قابل اثبات ساخت و از این ضریب بتا برای پیشبینی آینده در یک مدل آیندهنگر استفاده کرد.
1- ابتدا بیایید یک تابع احتمال به صورت زیر بسازیم.
P (X=x) = p^x (1-p)^(1-x)
در این رابطه احتمالی، p به معنای احتمال موفقیت و (1-p) به معنای احتمال شکست است.
تعریف پیشامد موفقیت میتواند توسط هر کاربر به دلخواه تعریف شود. به عنوان مثال موفقیت میتواند کسب سود در یک معامله، پیروزی در یک مسابقه، قبول شدن در یک آزمون و .... تعریف شود.
مقدار x میتواند به صورت عدد یک (موفقیت) و یا عدد صفر (شکست) تعریف شود. علامت ^ نیز به عنوان توان تعریف میشود.
دقت کنید من در اینجا به عمد از علامت ضرب استفاده نمیکنم و x را در توان p قرار دادهام.
در این رابطه احتمالی اگر موفقیت رخ دهد یعنی x = 1 باشد، فرمول زیر را خواهیم داشت.
P (X=1) = p^1 (1-p)^(1-1) = p^1 (1-p)^0 = p
یعنی با احتمال p موفقیت رخ خواهد داد و اگر شکست رخ دهد خواهیم داشت
P (X=0) = p^0 (1-p)^(1-0) = p^0 (1-p)^1 = (1-p)
یعنی با احتمال 1-p شکست رخ میدهد. بنابراین رابطه احتمالی که در بالا تعریف کردیم، درست کار میکند و صحیح است.
2- بیایید رابطه احتمالی خود را بازنویسی کنیم. من آن را به صورت زیر نوشتهام.
P (X=x) = p^x (1-p)^(1-x) =
(p/1-p)^x (1-p) = exp {xln(p/1-p)}+(1-p)
چرا من این کار را انجام میدهم؟ چرا رابطه احتمالی خود را به صورت exp (عدد نپر) و نمایی تعریف میکنم؟
برای پاسخ به این سوال به آن ln(p/1-p) که در رابطه احتمالی بالا به x متصل است، نگاه کنید.
چه چیزی به ذهن شما میرسد؟ به خاطر بیاورید ضریب بتا نیز چنین حالتی داشت و به x (و یا t در یک روند قیمتی) متصل بود.
هدف ما هم این است که بین b ضریب بتا که گذشتهنگر است و p که احتمال موفقیت در آینده را نشان میدهد یک رابطه اثبات شده ریاضی بسازیم.
3- من به رابطه ln(p/1-p) پارامتر طبیعی توزیع احتمال ساخته شده و به p/1-p که احتمال موفقیت به شکست است، نسبت احتمال، میگویم.
4- میدانیم که یک مدل رگرسیونی به صورت تابعی از x ها ساخته میشود. به صورت زیر
Y = f (x_1, x_2, …., x_k)
در اینجا اگر Y قیمت و x نیز زمان باشد به همان رابطه تعریف شده در ابتدای متن میرسیم. یعنی
Y = b_0 + b_1t
حال بیایید ln(p/1-p) که پارامتر طبیعی توزیع احتمال است را به عنوان Y تعریف کنیم. خواهیم داشت
Ln (p/1-p) = b_0 + b_1t
این رابطه را میتوانیم با exp گرفتن از طرفین رابطه به صورت زیر بنویسیم.
p/1-p = exp { b_0 + b_1t}
رابطه بالا همان چیزی است که ما به دنبال آن هستیم.
یعنی ساختن فرمولی جهت برقراری ارتباط ریاضی بین صریب بتا (b) با احتمال رخداد یک پیشامد.
5- آنچه در بالا ساختیم به ما میگوید چنانچه میخواهید احتمال موفقیت یک پیشامد را به دست بیاورید، کافی است ضریب بتا آن را به توان عدد نپر برسانید.
ضریب بتا عددی است که برای هر نماد متفاوت است و میتواند به صورت روزانه، هفتگی، ماهانه و .... برای هر نماد به دست بیاید. بنابراین عدد p/1-p نیز میتواند برای هر نماد متفاوت و خاص خود آن نماد باشد.
6- آنچه من میتوانم در اینجا به آن تاکید کنم اینکه لازم است در کنار تمام شاخصها و مولفههایی که برای هر نماد معرفی میشود (مانند P/E، DPS و ....) و معمولاً گذشتهنگر هستند، شاخصی با عنوان OR = p/1-p که آیندهنگر است، تعریف شود و کنار همان نماد قرار گیرد.
Y = b_0 + b_1X
در این مدل ساده، Y همان قیمت و X زمان است. بنابراین مدل بالا را به صورت درستتر میتوان به صورت زیر نوشت.
Y = b_0 + b_1t
همچنین b نیز همان ضریب بتا که میتواند عددی از منفی تا مثبت بینهایت باشد و محدودیتی ندارد.
نکته مهمی که وجود دارد این است که این یک مدل رگرسیونی گذشتهنگر است. یعنی ما بر مبنای دادههای قبلی به برازش و یافتن یک مدل میپردازیم.
از این مدل گذشته نگر نیز انتظار داریم، مبنایی برای رفتار حرکت قیمت در آینده باشد. البته واضح است که این انتظار نمیتواند همواره درست باشد و دلیلی ندارد آنچه در گذشته اتفاق افتاده، مسیری برای آینده نیز باشد.
موضوعی که من میخواهم در این متن به آن اشاره کنم این است که چگونه میتوان یک تئوری و رابطه ریاضی قابل اثبات ساخت و از این ضریب بتا برای پیشبینی آینده در یک مدل آیندهنگر استفاده کرد.
1- ابتدا بیایید یک تابع احتمال به صورت زیر بسازیم.
P (X=x) = p^x (1-p)^(1-x)
در این رابطه احتمالی، p به معنای احتمال موفقیت و (1-p) به معنای احتمال شکست است.
تعریف پیشامد موفقیت میتواند توسط هر کاربر به دلخواه تعریف شود. به عنوان مثال موفقیت میتواند کسب سود در یک معامله، پیروزی در یک مسابقه، قبول شدن در یک آزمون و .... تعریف شود.
مقدار x میتواند به صورت عدد یک (موفقیت) و یا عدد صفر (شکست) تعریف شود. علامت ^ نیز به عنوان توان تعریف میشود.
دقت کنید من در اینجا به عمد از علامت ضرب استفاده نمیکنم و x را در توان p قرار دادهام.
در این رابطه احتمالی اگر موفقیت رخ دهد یعنی x = 1 باشد، فرمول زیر را خواهیم داشت.
P (X=1) = p^1 (1-p)^(1-1) = p^1 (1-p)^0 = p
یعنی با احتمال p موفقیت رخ خواهد داد و اگر شکست رخ دهد خواهیم داشت
P (X=0) = p^0 (1-p)^(1-0) = p^0 (1-p)^1 = (1-p)
یعنی با احتمال 1-p شکست رخ میدهد. بنابراین رابطه احتمالی که در بالا تعریف کردیم، درست کار میکند و صحیح است.
2- بیایید رابطه احتمالی خود را بازنویسی کنیم. من آن را به صورت زیر نوشتهام.
P (X=x) = p^x (1-p)^(1-x) =
(p/1-p)^x (1-p) = exp {xln(p/1-p)}+(1-p)
چرا من این کار را انجام میدهم؟ چرا رابطه احتمالی خود را به صورت exp (عدد نپر) و نمایی تعریف میکنم؟
برای پاسخ به این سوال به آن ln(p/1-p) که در رابطه احتمالی بالا به x متصل است، نگاه کنید.
چه چیزی به ذهن شما میرسد؟ به خاطر بیاورید ضریب بتا نیز چنین حالتی داشت و به x (و یا t در یک روند قیمتی) متصل بود.
هدف ما هم این است که بین b ضریب بتا که گذشتهنگر است و p که احتمال موفقیت در آینده را نشان میدهد یک رابطه اثبات شده ریاضی بسازیم.
3- من به رابطه ln(p/1-p) پارامتر طبیعی توزیع احتمال ساخته شده و به p/1-p که احتمال موفقیت به شکست است، نسبت احتمال، میگویم.
4- میدانیم که یک مدل رگرسیونی به صورت تابعی از x ها ساخته میشود. به صورت زیر
Y = f (x_1, x_2, …., x_k)
در اینجا اگر Y قیمت و x نیز زمان باشد به همان رابطه تعریف شده در ابتدای متن میرسیم. یعنی
Y = b_0 + b_1t
حال بیایید ln(p/1-p) که پارامتر طبیعی توزیع احتمال است را به عنوان Y تعریف کنیم. خواهیم داشت
Ln (p/1-p) = b_0 + b_1t
این رابطه را میتوانیم با exp گرفتن از طرفین رابطه به صورت زیر بنویسیم.
p/1-p = exp { b_0 + b_1t}
رابطه بالا همان چیزی است که ما به دنبال آن هستیم.
یعنی ساختن فرمولی جهت برقراری ارتباط ریاضی بین صریب بتا (b) با احتمال رخداد یک پیشامد.
5- آنچه در بالا ساختیم به ما میگوید چنانچه میخواهید احتمال موفقیت یک پیشامد را به دست بیاورید، کافی است ضریب بتا آن را به توان عدد نپر برسانید.
ضریب بتا عددی است که برای هر نماد متفاوت است و میتواند به صورت روزانه، هفتگی، ماهانه و .... برای هر نماد به دست بیاید. بنابراین عدد p/1-p نیز میتواند برای هر نماد متفاوت و خاص خود آن نماد باشد.
6- آنچه من میتوانم در اینجا به آن تاکید کنم اینکه لازم است در کنار تمام شاخصها و مولفههایی که برای هر نماد معرفی میشود (مانند P/E، DPS و ....) و معمولاً گذشتهنگر هستند، شاخصی با عنوان OR = p/1-p که آیندهنگر است، تعریف شود و کنار همان نماد قرار گیرد.
عدد OR به ما نشان میدهد خرید این نماد چقدر شانس و احتمال موفقیت (سود) در آینده برای ما خواهد داشت.
هر چقدر این عدد کوچکتر از یک باشد (دقت کنید OR همیشه مثبت و بزرگتر از صفر است) بیانگر احتمال کمتر موفقیت در آینده است. مثلاً اگر برای نمادی عدد OR = p/1-p آن برابر با 0.4 باشد، به معنای این است که احتمال ضرر آینده در این نماد 1/0.4 = 2.5 برابر احتمال سود است. به عبارت دیگر خرید این نماد شانس 2.5 برابری ضرر در برابر سود را خواهد داشت.
هر چقدر عدد OR بزرگتر از یک باشد، بیانگر احتمال بزرگتر موفقیت در برابر شکست (ضرر) است. به عنوان مثال اگر برای نمادی عدد OR = p/1-p آن برابر با 2.7 باشد، به معنای این است که احتمال موفقیت آینده یعنی سود، 2.7 برابر احتمال شکست یعنی ضرر در این نماد است.
7- آنچه من در این متن به آن پرداختم فقط برای نمادهای بازار بورس نیست، بلکه برای هر پدیدهای که در طول زمان t حرکت میکند، برقرار و ثابت است.
محاسبه p/1-p از آنجا که به صورت تابعی از ضریب بتا تعریف شد، یعنی
p/1-p = e^b
ساده است و نرمافزارها به سادگی میتوانند آن را محاسبه کرده و عدد آن را کنار هر نماد به منظور درک درست و بهتری از آینده قرار دهند.
هر چقدر این عدد کوچکتر از یک باشد (دقت کنید OR همیشه مثبت و بزرگتر از صفر است) بیانگر احتمال کمتر موفقیت در آینده است. مثلاً اگر برای نمادی عدد OR = p/1-p آن برابر با 0.4 باشد، به معنای این است که احتمال ضرر آینده در این نماد 1/0.4 = 2.5 برابر احتمال سود است. به عبارت دیگر خرید این نماد شانس 2.5 برابری ضرر در برابر سود را خواهد داشت.
هر چقدر عدد OR بزرگتر از یک باشد، بیانگر احتمال بزرگتر موفقیت در برابر شکست (ضرر) است. به عنوان مثال اگر برای نمادی عدد OR = p/1-p آن برابر با 2.7 باشد، به معنای این است که احتمال موفقیت آینده یعنی سود، 2.7 برابر احتمال شکست یعنی ضرر در این نماد است.
7- آنچه من در این متن به آن پرداختم فقط برای نمادهای بازار بورس نیست، بلکه برای هر پدیدهای که در طول زمان t حرکت میکند، برقرار و ثابت است.
محاسبه p/1-p از آنجا که به صورت تابعی از ضریب بتا تعریف شد، یعنی
p/1-p = e^b
ساده است و نرمافزارها به سادگی میتوانند آن را محاسبه کرده و عدد آن را کنار هر نماد به منظور درک درست و بهتری از آینده قرار دهند.
1- آنچه من در متن بالا نوشتم، براورد، پیشبینی و یا تخمین نیست. اصولاً متن بالا آمار نیست. بلکه ریاضیات است که با قضیه و اصل قابل اثبات روبهرو است.
یعنی اثبات ریاضی میشود که نسبت موفقیت به شکست در پدیدهای که در طول زمان حرکت میکند، برابر با EXP ضریب بتا و یا تانژانت زاویهای است که خط ترند با محور افق میسازد. یعنی
P/1-P = Exp {b} = Exp {Tangent θ}
2- خود من بهتر از هر کسی میدانم آنچه در اینجا نوشته و پیشنهاد میشود اعم از شاخص میانه، ایندکسهایی مانند PRB، PRD و یا AAD و یا همین اضافه شدن شاخص آیندهنگری مانند P/1-P قابلیت اجرایی دارند، منتهی تمایلی برای اجرا شدن ندارند.
گذشته از محدودیت خواننده، ابزاری جهت اجرا شدن نیز وجود ندارد. واضح است که هیچ سیستمی به شاخص میانه بازار بورس تهران که اکنون حدود 1.470 هزار واحد است و اگر با تورم تعدیل و Adjust شود کمتر از 705 هزار واحد خواهد شد، علاقهای ندارد. خود من بهتر میدانم که هیچ سیستمی نمیخواهد شاخص دوستداشتنی 2 میلیونی را رها کند و شاخص میانه شفاف و گزنده 700 هزار واحدی را نمایش دهد.
آنچه اینجا نوشته میشود، عمدتاً علائق شخصی جهت کار با دادهها است که بازخورد بیرونی ندارد. با این حال به نظرم لازم است نوشته شود شاید در آینده مورد استفاده و دیده شدن قرار گیرد.
3- تصویری که ارسال کردهام هیستوگرام عدد به دست آمده برای P/1-P است که در متن قبل به آن پرداختم. این عدد برای 630 نماد بازار به دست آمده است. در این رابطه چند نکته مینویسم.
الف) میانگین نسبت سود به زیان در آینده یعنی همان P/1-P که از Exp تانژانت زاویه ترند هر نماد با محور X (محور زمان) به دست میآید، عدد 1.7 است.
این مطلب به معنای این است که در آینده سود 1.7 برابر احتمال وقوع بیشتری نسبت به ضرر دارد. البته به نظرم این عدد خوشبینانه است و سیاست سرکوب نقش بسته در ذهن سیستم، آن را تعدیل و تا حدی کاهش خواهد داد.
با این حال همچنان عدد P/1-P بزرگتر از یک و عددی بین 1.4 تا 1.5 واحد خواهد بود. سادهتر بخواهم بگویم این است که احتمال سود حدود 40 تا 50 درصد از احتمال ضرر در بازار بیشتر است.
ب) هیستوگرام P/1-P در گراف بالا نشان میدهد نمادهایی با نسبت سود به زیان 8-7 وجود دارند (نام آنها محفوظ است) همچنین نمادهایی با نسبت P/1-P حدود 0.01 نیز دیده میشوند (یعنی احتمال ضرر در این نمادها صد برابر احتمال سود است، نام این نمادها نیز محفوظ است).
از طرف دیگر فاصله اطمینان میانگین P/1-p آینده بازار عددی بین 1.4 تا 1.7 به دست میآید. این مطلب نشان میدهد حتی انتخاب تصادفی میتواند نتیجهای بهتر از انتخاب از بین نمادهای با P/1-P کوچکتر از یک، داشته باشد.
پ) نمادها اگر به دو دسته OR = P/1-P بزرگتر و کوچکتر از یک (OR>1) و (OR<1) تقسیم شوند، میانگین P/1-P نمادها در گروه OR > 1 برابر با 2.14 (در این گروه 460 نماد قرار دارند) و در گروه نمادهای با OR < 1 برابر با 0.47 (در این گروه 170 نماد قرار دارند) خواهد بود.
این اعداد نشان میدهد ما نمیتوانیم احتمال بسیار بزرگی برای سود و یا احتمال زیادی برای ضرر متصور شویم. هر چند باید بیان کرد که احتمال سود بیشتر از احتمال ضرر است، این مطلب از آن جهت اهمیت دارد که ما در چند سال گذشته مرتب با چشمانداز امیدریاضی منفی (یعنی احتمال بیشتر ضرر) روبهرو بودهایم. یعنی وقتی در پایان سال به بررسی سال آینده میپرداختیم بیان میکردیم که امیدریاضی سود در سال آینده منفی است. در این زمینه میتوانید متنهای قبلی را ببینید.
بنابراین میتوان چنین نتیجه گرفت که برخلاف سالهای گذشته، چشم انداز آینده مثبت و احتمال سوددهی بیشتر از ضرر خواهد بود.
البته باز هم تاکید میکنم که Exp {Beta} ها نشان میدهد این سوددهی بسیار زیاد و بزرگ نخواهد بود.
https://graphpad.ir/wp-content/uploads/2024/02/Odds-Ratio-GraphPad.ir_.png
یعنی اثبات ریاضی میشود که نسبت موفقیت به شکست در پدیدهای که در طول زمان حرکت میکند، برابر با EXP ضریب بتا و یا تانژانت زاویهای است که خط ترند با محور افق میسازد. یعنی
P/1-P = Exp {b} = Exp {Tangent θ}
2- خود من بهتر از هر کسی میدانم آنچه در اینجا نوشته و پیشنهاد میشود اعم از شاخص میانه، ایندکسهایی مانند PRB، PRD و یا AAD و یا همین اضافه شدن شاخص آیندهنگری مانند P/1-P قابلیت اجرایی دارند، منتهی تمایلی برای اجرا شدن ندارند.
گذشته از محدودیت خواننده، ابزاری جهت اجرا شدن نیز وجود ندارد. واضح است که هیچ سیستمی به شاخص میانه بازار بورس تهران که اکنون حدود 1.470 هزار واحد است و اگر با تورم تعدیل و Adjust شود کمتر از 705 هزار واحد خواهد شد، علاقهای ندارد. خود من بهتر میدانم که هیچ سیستمی نمیخواهد شاخص دوستداشتنی 2 میلیونی را رها کند و شاخص میانه شفاف و گزنده 700 هزار واحدی را نمایش دهد.
آنچه اینجا نوشته میشود، عمدتاً علائق شخصی جهت کار با دادهها است که بازخورد بیرونی ندارد. با این حال به نظرم لازم است نوشته شود شاید در آینده مورد استفاده و دیده شدن قرار گیرد.
3- تصویری که ارسال کردهام هیستوگرام عدد به دست آمده برای P/1-P است که در متن قبل به آن پرداختم. این عدد برای 630 نماد بازار به دست آمده است. در این رابطه چند نکته مینویسم.
الف) میانگین نسبت سود به زیان در آینده یعنی همان P/1-P که از Exp تانژانت زاویه ترند هر نماد با محور X (محور زمان) به دست میآید، عدد 1.7 است.
این مطلب به معنای این است که در آینده سود 1.7 برابر احتمال وقوع بیشتری نسبت به ضرر دارد. البته به نظرم این عدد خوشبینانه است و سیاست سرکوب نقش بسته در ذهن سیستم، آن را تعدیل و تا حدی کاهش خواهد داد.
با این حال همچنان عدد P/1-P بزرگتر از یک و عددی بین 1.4 تا 1.5 واحد خواهد بود. سادهتر بخواهم بگویم این است که احتمال سود حدود 40 تا 50 درصد از احتمال ضرر در بازار بیشتر است.
ب) هیستوگرام P/1-P در گراف بالا نشان میدهد نمادهایی با نسبت سود به زیان 8-7 وجود دارند (نام آنها محفوظ است) همچنین نمادهایی با نسبت P/1-P حدود 0.01 نیز دیده میشوند (یعنی احتمال ضرر در این نمادها صد برابر احتمال سود است، نام این نمادها نیز محفوظ است).
از طرف دیگر فاصله اطمینان میانگین P/1-p آینده بازار عددی بین 1.4 تا 1.7 به دست میآید. این مطلب نشان میدهد حتی انتخاب تصادفی میتواند نتیجهای بهتر از انتخاب از بین نمادهای با P/1-P کوچکتر از یک، داشته باشد.
پ) نمادها اگر به دو دسته OR = P/1-P بزرگتر و کوچکتر از یک (OR>1) و (OR<1) تقسیم شوند، میانگین P/1-P نمادها در گروه OR > 1 برابر با 2.14 (در این گروه 460 نماد قرار دارند) و در گروه نمادهای با OR < 1 برابر با 0.47 (در این گروه 170 نماد قرار دارند) خواهد بود.
این اعداد نشان میدهد ما نمیتوانیم احتمال بسیار بزرگی برای سود و یا احتمال زیادی برای ضرر متصور شویم. هر چند باید بیان کرد که احتمال سود بیشتر از احتمال ضرر است، این مطلب از آن جهت اهمیت دارد که ما در چند سال گذشته مرتب با چشمانداز امیدریاضی منفی (یعنی احتمال بیشتر ضرر) روبهرو بودهایم. یعنی وقتی در پایان سال به بررسی سال آینده میپرداختیم بیان میکردیم که امیدریاضی سود در سال آینده منفی است. در این زمینه میتوانید متنهای قبلی را ببینید.
بنابراین میتوان چنین نتیجه گرفت که برخلاف سالهای گذشته، چشم انداز آینده مثبت و احتمال سوددهی بیشتر از ضرر خواهد بود.
البته باز هم تاکید میکنم که Exp {Beta} ها نشان میدهد این سوددهی بسیار زیاد و بزرگ نخواهد بود.
https://graphpad.ir/wp-content/uploads/2024/02/Odds-Ratio-GraphPad.ir_.png
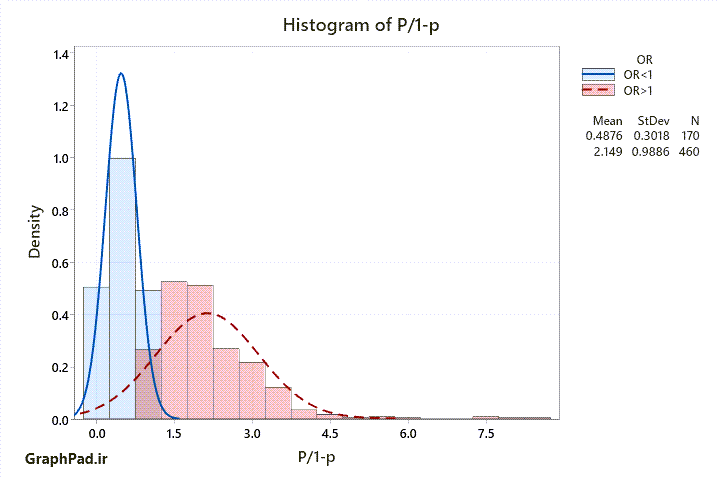{kind=link}
میتوان گفت همهی مقالاتی که با استفاده از Survival Analysis به بررسی تاثیر نماز خواندن، دعا کردن و عبادت (من از مفهوم عام آن به معنای توجه به الاهیت و خالق در هر دین و آیینی حرف میزنم)، منحنی بقایی شبیه به گرافهای پیوست دارند.
این گرافها نشان میدهند نرخ بقا Survival Rate و زنده ماندن در افرادی که عبادت میکنند به صورت معنادار بیشتر از افرادی است که عبادت نمیکنند.
1- مقالهای که در 29 July 2023 در Springer نمایه شده است، نشان میدهد بقا و نرخ زنده ماندن عبادت کنندگان بیش از 6 سال بیشتر از سایر افراد بوده است. این مطالعه از دو جهت دارای اهمیت است. اول اینکه نویسندگان بسیار تلاش کردهاند افراد مطالعه از نظر زیستپزشکی، جمعیتشناختی، روانی، اقتصادی و بهداشتی مشابه یکدیگر باشند. به معنای اینکه آنها سعی کردهاند همهی Variable ها را کنترل کرده و تنها تفاوت افراد، در عبادت کردن یا نکردن باشد.
موضوع دیگر مهم در این مقاله بررسی فراوانی و تعداد دفعات عبادت در بین افراد بوده است. در واقع این مطالعه فقط باینری (صفر و یک نیست) بلکه Ordinal و رتبهای است. نویسندگان از 8 رده جهت بررسی فراوانی تاثیر عبادت بر سلامت و زندهمانی به شرح زیر استفاده کردهاند.
It was measured on a 1 to 8 scale (1 = Never, 2 = Less than once a month, 3 = Once a month, 4 = A few times a month, 5 = Once a week, 6 = a few times a week, 7 = Once a day, and 8 = Several times a day)
گراف و نتیجه به دست آمده نشان میدهد نه فقط عبادت، بلکه تعدد و فراوانی آن، نرخ زندهمانی را افزایش و سرعت مرگ را کاهش میدهد. علاقمند بودید متن مقاله را در این لینک ببینید.
2- مقاله دیگری که در 23 Aug 2022 در National Library of Medicine (NIH) منتشر شده است، نرخ بقا را 17 سال بیشتر بیان میکند. این مقاله را ببینید. من Survival Curve آن را در این متن آوردهام.
3- علاقمند بودید یک Meta-Analysis در این زمینه در این لینک را هم ببینید. این متا آنالیز به بررسی همزمان 15 مقاله دیگر در زمینه تاثیر عبادت بر سلامت و نرخ بقا انسان پرداخته است.
پینوشت. واضح است که نه من به عنوان نویسنده و نه شما به عنوان خواننده در یک فضای ذهنی سیاستزده به سر نمیبریم که بخواهیم به تعریف و بیان کسی یا چیزی بپردازیم. آنچه من علاقمند بودم و برای خودم اصرار داشتم که آن را در گراف پد بنویسم، بیان حقیقتی است که علم آن را تایید میکند.
https://graphpad.ir/wp-content/uploads/2024/02/Survival-Curve-GraphPad.ir_.png
این گرافها نشان میدهند نرخ بقا Survival Rate و زنده ماندن در افرادی که عبادت میکنند به صورت معنادار بیشتر از افرادی است که عبادت نمیکنند.
1- مقالهای که در 29 July 2023 در Springer نمایه شده است، نشان میدهد بقا و نرخ زنده ماندن عبادت کنندگان بیش از 6 سال بیشتر از سایر افراد بوده است. این مطالعه از دو جهت دارای اهمیت است. اول اینکه نویسندگان بسیار تلاش کردهاند افراد مطالعه از نظر زیستپزشکی، جمعیتشناختی، روانی، اقتصادی و بهداشتی مشابه یکدیگر باشند. به معنای اینکه آنها سعی کردهاند همهی Variable ها را کنترل کرده و تنها تفاوت افراد، در عبادت کردن یا نکردن باشد.
موضوع دیگر مهم در این مقاله بررسی فراوانی و تعداد دفعات عبادت در بین افراد بوده است. در واقع این مطالعه فقط باینری (صفر و یک نیست) بلکه Ordinal و رتبهای است. نویسندگان از 8 رده جهت بررسی فراوانی تاثیر عبادت بر سلامت و زندهمانی به شرح زیر استفاده کردهاند.
It was measured on a 1 to 8 scale (1 = Never, 2 = Less than once a month, 3 = Once a month, 4 = A few times a month, 5 = Once a week, 6 = a few times a week, 7 = Once a day, and 8 = Several times a day)
گراف و نتیجه به دست آمده نشان میدهد نه فقط عبادت، بلکه تعدد و فراوانی آن، نرخ زندهمانی را افزایش و سرعت مرگ را کاهش میدهد. علاقمند بودید متن مقاله را در این لینک ببینید.
2- مقاله دیگری که در 23 Aug 2022 در National Library of Medicine (NIH) منتشر شده است، نرخ بقا را 17 سال بیشتر بیان میکند. این مقاله را ببینید. من Survival Curve آن را در این متن آوردهام.
3- علاقمند بودید یک Meta-Analysis در این زمینه در این لینک را هم ببینید. این متا آنالیز به بررسی همزمان 15 مقاله دیگر در زمینه تاثیر عبادت بر سلامت و نرخ بقا انسان پرداخته است.
پینوشت. واضح است که نه من به عنوان نویسنده و نه شما به عنوان خواننده در یک فضای ذهنی سیاستزده به سر نمیبریم که بخواهیم به تعریف و بیان کسی یا چیزی بپردازیم. آنچه من علاقمند بودم و برای خودم اصرار داشتم که آن را در گراف پد بنویسم، بیان حقیقتی است که علم آن را تایید میکند.
https://graphpad.ir/wp-content/uploads/2024/02/Survival-Curve-GraphPad.ir_.png
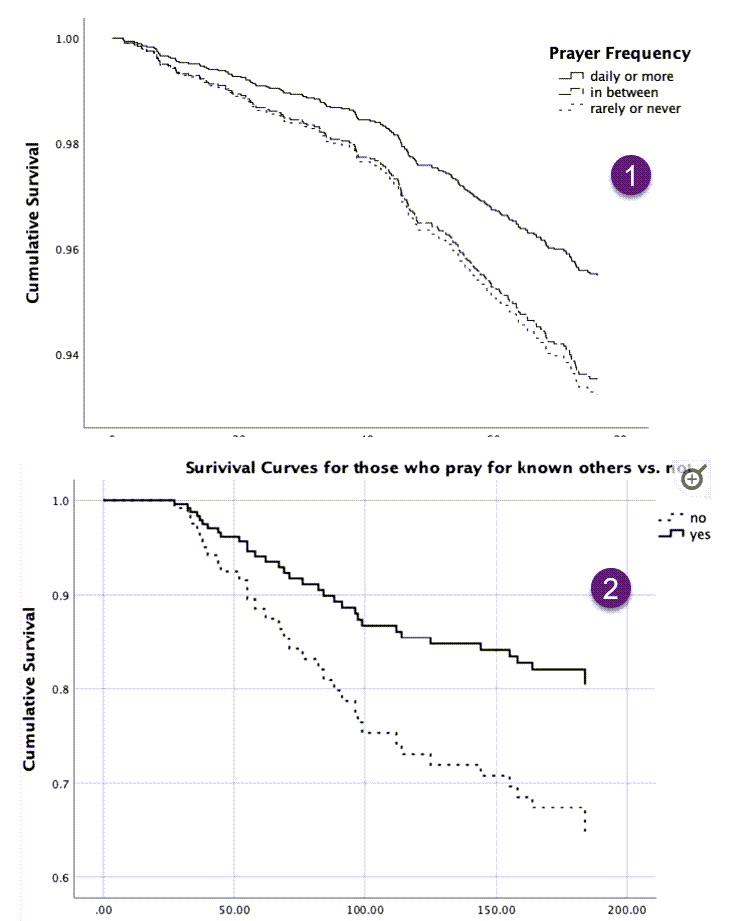{kind=link}